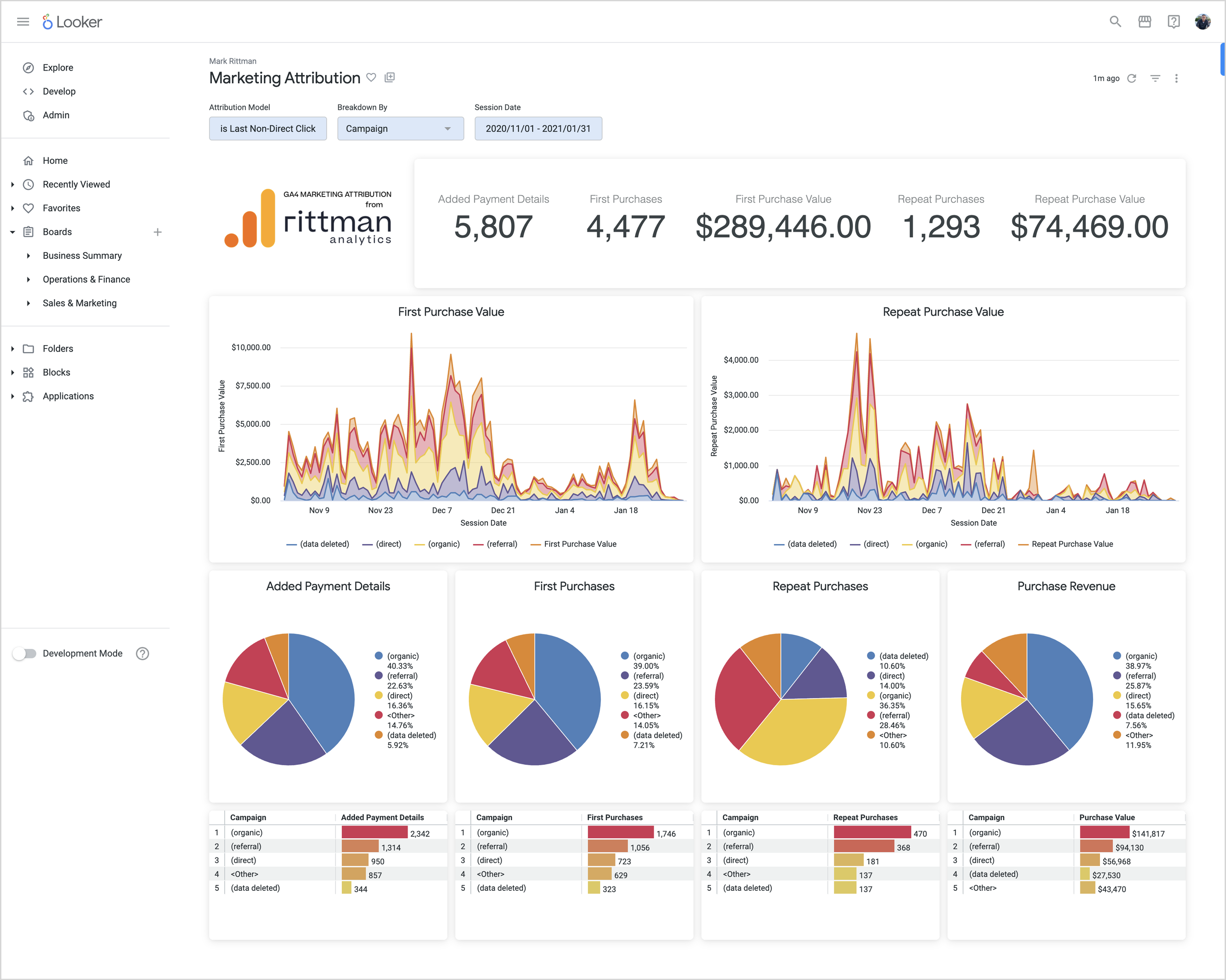
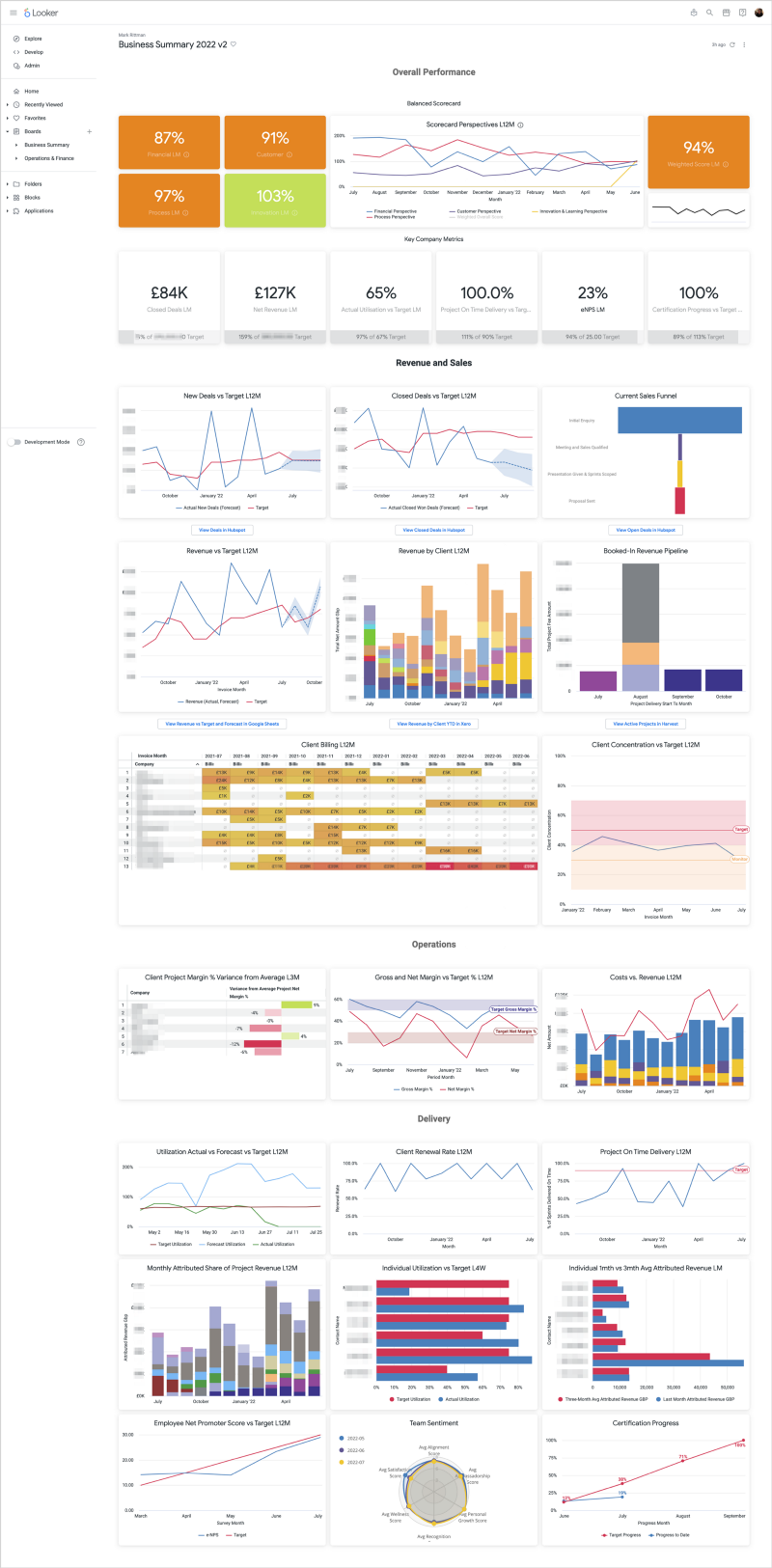
Latest Articles | Modern Data Stack | Marketing Analytics | Looker | Tips & Techniques | AI & GenAI | Conferences & Webinars Featured Blogs 5 Feb 2024 Artificial Intelligence Generative AI Comes to Looker via Vertex AI and BigQuery BQML 5 Feb 2024 Artificial Intelligence 5 Feb 2024 Artificial Intelligence 9 May 2023 Marketing Analytics Building your Own GA4 Rules-Based Marketing Attribution Models using Google BigQuery and Looker 9 May 2023 Marketing Analytics 9 May 2023 Marketing Analytics 19 Jul 2022 Looker KPI Dashboards and Balanced Scorecards using Looker, dbt and Google BigQuery 19 Jul 2022 Looker 19 Jul 2022 Looker 30 May 2022 Marketing Analytics Stitching Identity Across the Customer Journey Using Segment, Google BigQuery and Looker 30 May 2022 Marketing Analytics 30 May 2022 Marketing Analytics Conferences & Webinars Mark Rittman 19/06/2023 Conferences & Webinars Mark Rittman 19/06/2023 Wednesday Webinar Series : “How Rittman Analytics Builds Modern Data Stacks using Cube, Preset and Dagster” - Wednesday 28th June 2023 Read More Oracle Mark Rittman 25/09/2016 Oracle Mark Rittman 25/09/2016 OBIEE12c — Pushing-Up Daisies … or more Relevant than Ever in the World of BiModal IT? Read More Uncategorized Mark Rittman 25/09/2016 Uncategorized Mark Rittman 25/09/2016 Last-Stop Budapest … And Five New BI and Analytics Technologies Coming Soon for Hadoop Read More Uncategorized Mark Rittman 25/09/2016 Uncategorized Mark Rittman 25/09/2016 From lots of reports (with some data Analysis) to Massive Data Analysis (With some Reporting) Read More Uncategorized Mark Rittman 25/09/2016 Uncategorized Mark Rittman 25/09/2016 Building Predictive Analytics Models against Wearables, Smart Home and Smartphone App Data — Here’s… Read More
Conferences & Webinars Mark Rittman 19/06/2023 Conferences & Webinars Mark Rittman 19/06/2023 Wednesday Webinar Series : “How Rittman Analytics Builds Modern Data Stacks using Cube, Preset and Dagster” - Wednesday 28th June 2023 Read More
Oracle Mark Rittman 25/09/2016 Oracle Mark Rittman 25/09/2016 OBIEE12c — Pushing-Up Daisies … or more Relevant than Ever in the World of BiModal IT? Read More
Uncategorized Mark Rittman 25/09/2016 Uncategorized Mark Rittman 25/09/2016 Last-Stop Budapest … And Five New BI and Analytics Technologies Coming Soon for Hadoop Read More
Uncategorized Mark Rittman 25/09/2016 Uncategorized Mark Rittman 25/09/2016 From lots of reports (with some data Analysis) to Massive Data Analysis (With some Reporting) Read More
Uncategorized Mark Rittman 25/09/2016 Uncategorized Mark Rittman 25/09/2016 Building Predictive Analytics Models against Wearables, Smart Home and Smartphone App Data — Here’s… Read More