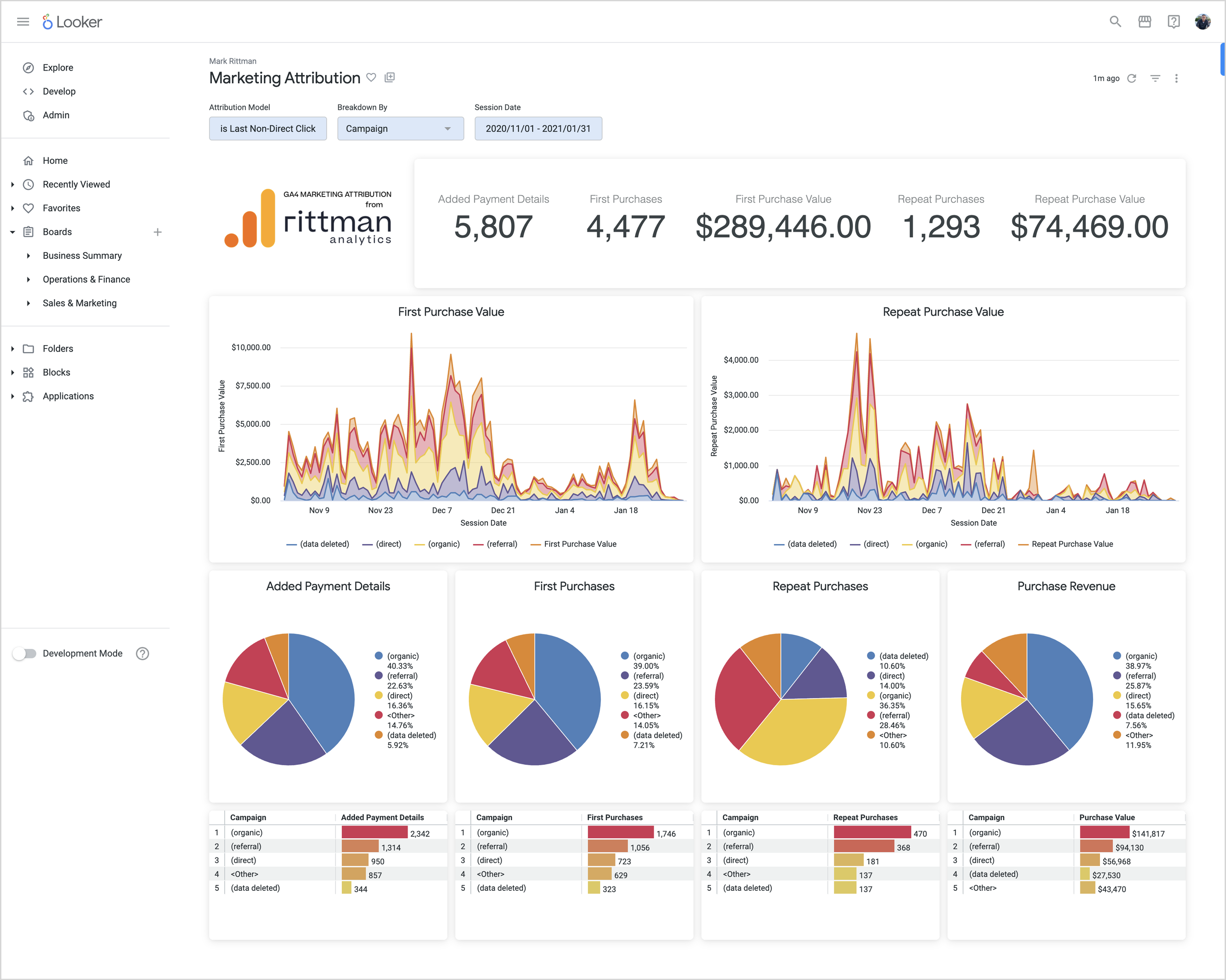
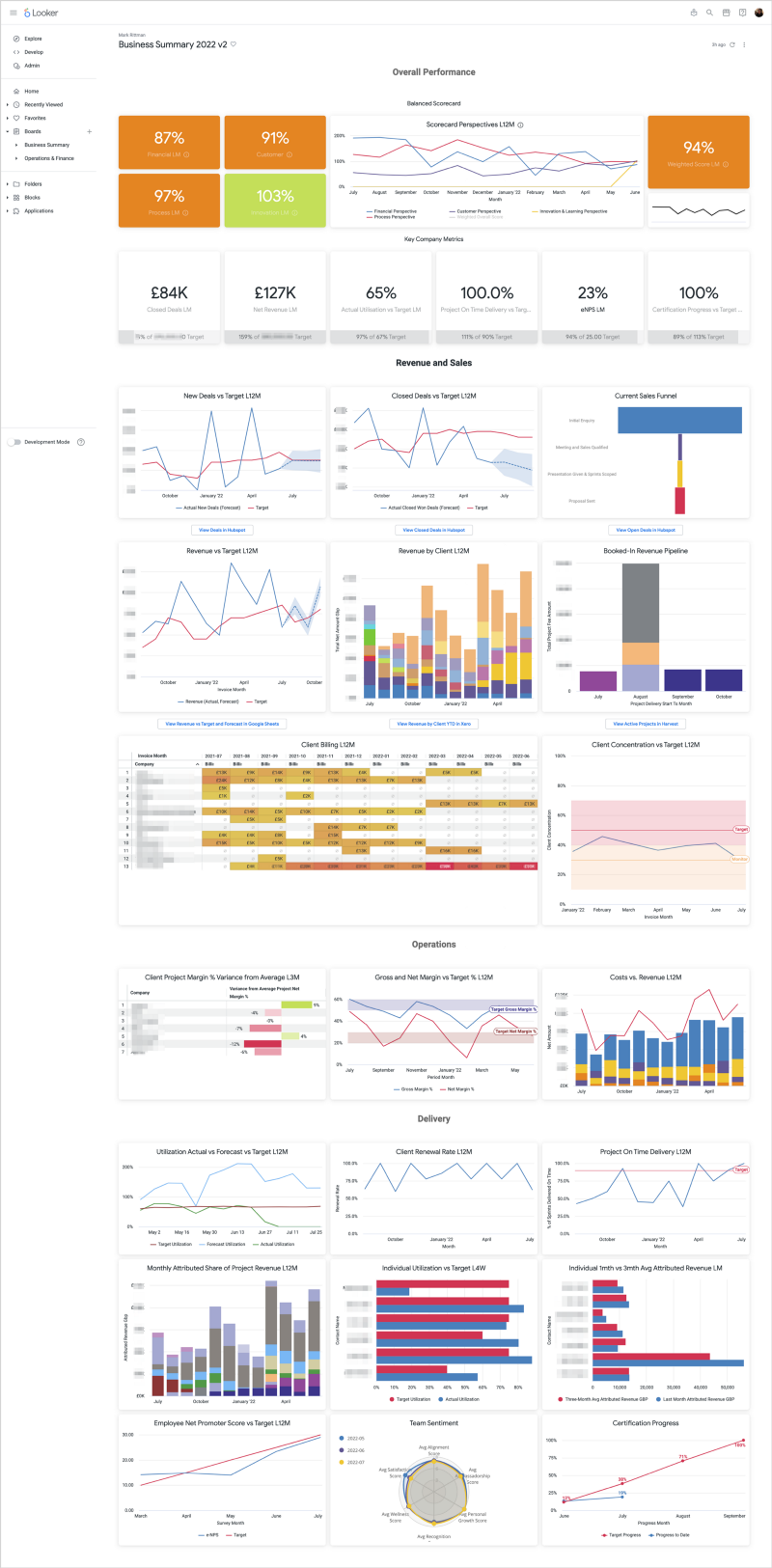
Latest Articles | Modern Data Stack | Marketing Analytics | Looker | Tips & Techniques | AI & GenAI | Conferences & Webinars Featured Blogs 5 Feb 2024 Artificial Intelligence Generative AI Comes to Looker via Vertex AI and BigQuery BQML 5 Feb 2024 Artificial Intelligence 5 Feb 2024 Artificial Intelligence 9 May 2023 Marketing Analytics Building your Own GA4 Rules-Based Marketing Attribution Models using Google BigQuery and Looker 9 May 2023 Marketing Analytics 9 May 2023 Marketing Analytics 19 Jul 2022 Looker KPI Dashboards and Balanced Scorecards using Looker, dbt and Google BigQuery 19 Jul 2022 Looker 19 Jul 2022 Looker 30 May 2022 Marketing Analytics Stitching Identity Across the Customer Journey Using Segment, Google BigQuery and Looker 30 May 2022 Marketing Analytics 30 May 2022 Marketing Analytics Uncategorized Mark Rittman 21/10/2017 Uncategorized Mark Rittman 21/10/2017 Druid, Imply and Looker 5 bring OLAP Analysis to BigQuery’s Data Warehouse Read More Uncategorized Mark Rittman 29/05/2017 Uncategorized Mark Rittman 29/05/2017 Analytic Views, Oracle Database 12.2 Read More
Uncategorized Mark Rittman 21/10/2017 Uncategorized Mark Rittman 21/10/2017 Druid, Imply and Looker 5 bring OLAP Analysis to BigQuery’s Data Warehouse Read More
Uncategorized Mark Rittman 29/05/2017 Uncategorized Mark Rittman 29/05/2017 Analytic Views, Oracle Database 12.2 Read More