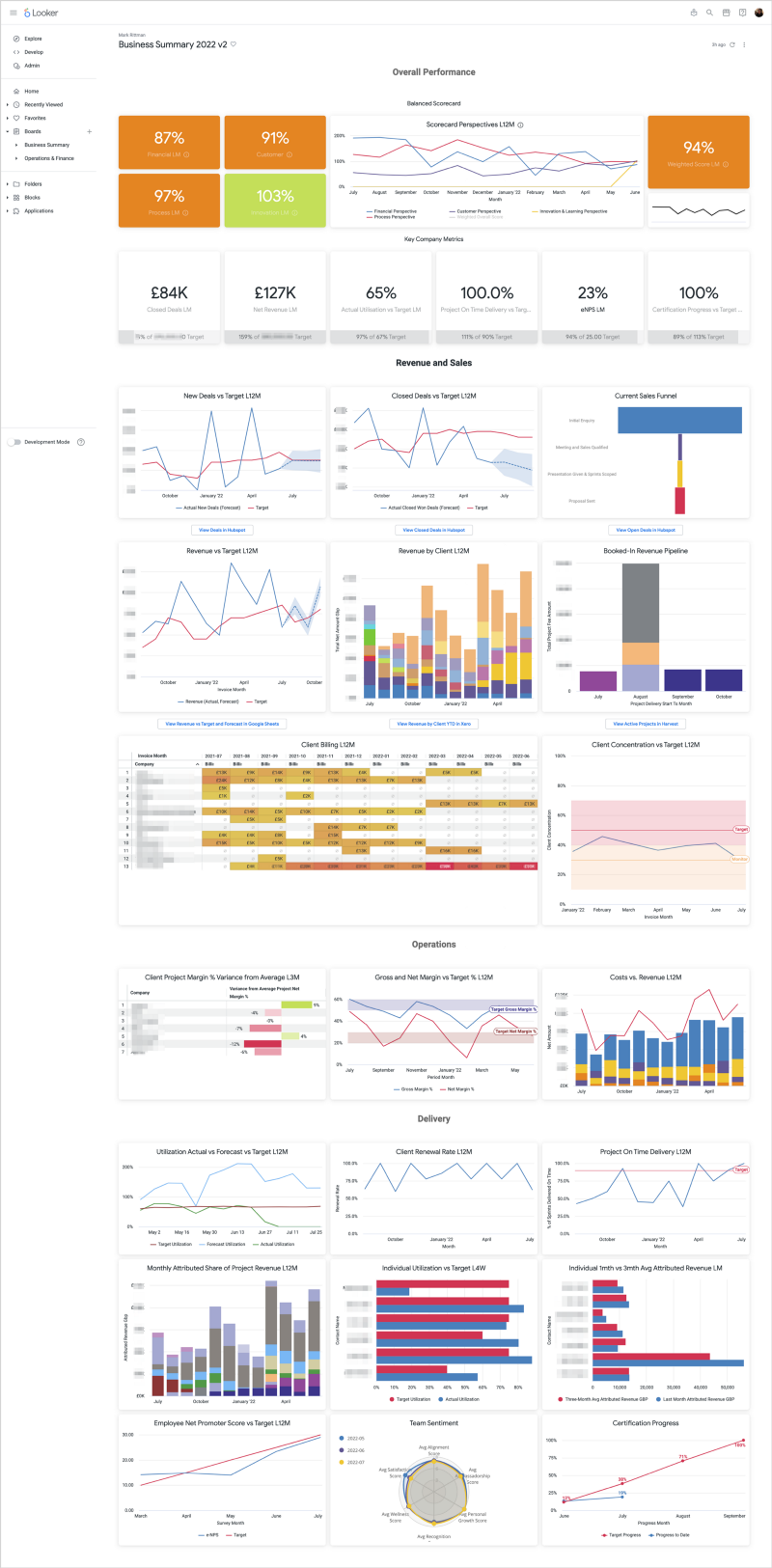
Latest Articles | Modern Data Stack | Marketing Analytics | Looker | Tips & Techniques | AI & GenAI | Conferences & Webinars Featured Blogs 5 Feb 2024 Artificial Intelligence Generative AI Comes to Looker via Vertex AI and BigQuery BQML 5 Feb 2024 Artificial Intelligence 5 Feb 2024 Artificial Intelligence 19 Jul 2022 Looker KPI Dashboards and Balanced Scorecards using Looker, dbt and Google BigQuery 19 Jul 2022 Looker 19 Jul 2022 Looker 30 May 2022 Marketing Analytics Stitching Identity Across the Customer Journey Using Segment, Google BigQuery and Looker 30 May 2022 Marketing Analytics 30 May 2022 Marketing Analytics 30 May 2022 Modern Data Stack How Rittman Analytics does Analytics Part 2 : Building our Modern Data Stack using dbt, Google BigQuery, Looker, Segment and Rudderstack. 30 May 2022 Modern Data Stack 30 May 2022 Modern Data Stack Uncategorized Mark Rittman 05/03/2019 Uncategorized Mark Rittman 05/03/2019 Drill to Detail Podcast Returns with Ep.60 'A Deeper Look Into Looker' With Special Guest Lloyd Tabb Read More Mark Rittman 21/01/2019 Mark Rittman 21/01/2019 Looker London Meetup on Thursday, February 7th 2019 - Registration Now Open! Read More Mark Rittman 27/11/2018 Mark Rittman 27/11/2018 MJR Analytics Sessions at UKOUG Tech'18, Liverpool ACC, 3rd-5th December 2018 Read More Oracle Mark Rittman 17/11/2018 Oracle Mark Rittman 17/11/2018 Five Thoughts About Thomas Kurian’s Move to become CEO of Google Cloud Platform Read More Mark Rittman 14/11/2018 Mark Rittman 14/11/2018 Slides and Forbes.com Article from "Data Warehouse Like a Tech Startup with Oracle Autonomous Data Warehouse Cloud" Read More Mark Rittman 12/11/2018 Mark Rittman 12/11/2018 Event-Level Digital Analytics using Google Analytics, Fivetran, BigQuery and Looker Read More Uncategorized Mark Rittman 11/11/2018 Uncategorized Mark Rittman 11/11/2018 Digital Analytics, BI and Big Data Meetup in Copenhagen 22.11.2018 Read More Mark Rittman 28/10/2018 Mark Rittman 28/10/2018 Media Analytics for the Drill to Detail Podcast using Looker, Fivetran and Mixpanel Read More Uncategorized Mark Rittman 22/10/2018 Uncategorized Mark Rittman 22/10/2018 MJR Analytics Presenting at Oracle Openworld 2018, San Francisco Read More Uncategorized Mark Rittman 17/09/2018 Uncategorized Mark Rittman 17/09/2018 Introducing MJR Analytics … and How Two Years Go So Fast When You’re Learning Something New Read More Uncategorized Mark Rittman 27/08/2018 Uncategorized Mark Rittman 27/08/2018 Date Partitioning and Table Clustering in Google BigQuery (and Looker PDTs) Read More Uncategorized Mark Rittman 02/06/2018 Uncategorized Mark Rittman 02/06/2018 Oracle Big Data Cloud, Event Hub and Analytics Cloud Data Lake Edition pt.3 Read More Newer Posts Older Posts
Uncategorized Mark Rittman 05/03/2019 Uncategorized Mark Rittman 05/03/2019 Drill to Detail Podcast Returns with Ep.60 'A Deeper Look Into Looker' With Special Guest Lloyd Tabb Read More
Mark Rittman 21/01/2019 Mark Rittman 21/01/2019 Looker London Meetup on Thursday, February 7th 2019 - Registration Now Open! Read More
Mark Rittman 27/11/2018 Mark Rittman 27/11/2018 MJR Analytics Sessions at UKOUG Tech'18, Liverpool ACC, 3rd-5th December 2018 Read More
Oracle Mark Rittman 17/11/2018 Oracle Mark Rittman 17/11/2018 Five Thoughts About Thomas Kurian’s Move to become CEO of Google Cloud Platform Read More
Mark Rittman 14/11/2018 Mark Rittman 14/11/2018 Slides and Forbes.com Article from "Data Warehouse Like a Tech Startup with Oracle Autonomous Data Warehouse Cloud" Read More
Mark Rittman 12/11/2018 Mark Rittman 12/11/2018 Event-Level Digital Analytics using Google Analytics, Fivetran, BigQuery and Looker Read More
Uncategorized Mark Rittman 11/11/2018 Uncategorized Mark Rittman 11/11/2018 Digital Analytics, BI and Big Data Meetup in Copenhagen 22.11.2018 Read More
Mark Rittman 28/10/2018 Mark Rittman 28/10/2018 Media Analytics for the Drill to Detail Podcast using Looker, Fivetran and Mixpanel Read More
Uncategorized Mark Rittman 22/10/2018 Uncategorized Mark Rittman 22/10/2018 MJR Analytics Presenting at Oracle Openworld 2018, San Francisco Read More
Uncategorized Mark Rittman 17/09/2018 Uncategorized Mark Rittman 17/09/2018 Introducing MJR Analytics … and How Two Years Go So Fast When You’re Learning Something New Read More
Uncategorized Mark Rittman 27/08/2018 Uncategorized Mark Rittman 27/08/2018 Date Partitioning and Table Clustering in Google BigQuery (and Looker PDTs) Read More
Uncategorized Mark Rittman 02/06/2018 Uncategorized Mark Rittman 02/06/2018 Oracle Big Data Cloud, Event Hub and Analytics Cloud Data Lake Edition pt.3 Read More