Drill to Detail Podcast Transcripts & Gen AI Insights Now Available, Powered by OpenAI Whisper API & BigQuery Colab Notebooks

Until recently doing episode transcription manually or through one of the first-generation online services was a long and tedious process but with services such as OpenAI’s Whisper API service now available that use generative AI technology, we created a BigQuery Colab Enterprise notebook that not only transcribed all of our past episodes but also generated episode summaries, lists of key points and speaker quotes that we wrote back to a BigQuery table and used as the data source for this new web app.
Leveraging BigQuery Colab Notebooks and the OpenAI Whisper API
If you’re interested in how we pulled these transcripts and episode insights together, the full python code can be found in this BigQuery notebook and, skipping-over the initial imports and setup of the BigQuery and OpenAI API clients we started first by defining functions that take a given podcast episode URL and download the episode MP3 file, then split that file into chunks to fit within the Whisper API file size limit.
def download_mp3(url, filename):
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
def split_audio(filename, chunk_length_ms=60000): # 1 minute chunks
audio = AudioSegment.from_mp3(filename)
chunks = []
for i in range(0, len(audio), chunk_length_ms):
chunk = audio[i:i+chunk_length_ms]
chunk_file = f"{filename}_chunk_{i//chunk_length_ms}.mp3"
chunk.export(chunk_file, format="mp3")
chunks.append(chunk_file)
return chunks
The next function performs the actual transcription, passing the mp3 file chunks to the Whisper API and returning the speech transcription.
def transcribe_audio(client, filename):
with open(filename, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
return transcript.text
And now the main body of code for the notebook sets-up modules to parse the RSS feed that we pass to the notebook in order to extract episode titles, links, descriptions and other metadata, process each episode in the feed and assemble the full episode transcription from all each episode’s chunk transcriptions.
def process_podcast(url):
feed = feedparser.parse(url)
episodes = []
for entry in feed.entries:
episode = {
'title': entry.get('title', ''),
'link': entry.get('link', ''),
'description': entry.get('description', ''),
'published': entry.get('published', ''),
}
audio_url = None
if 'links' in entry:
for link in entry.links:
if 'type' in link and link['type'].startswith('audio/'):
audio_url = link.get('href')
break
if not audio_url and 'enclosures' in entry:
for enclosure in entry.enclosures:
if 'type' in enclosure and enclosure['type'].startswith('audio/'):
audio_url = enclosure.get('href')
break
if audio_url:
episode['audio_url'] = audio_url
episodes.append(episode)
return episodes
def process_episode(client, episode):
print(f"Processing episode: {episode['title']}")
filename = f"temp_{episode['title'].replace(' ', '_')}.mp3"
download_mp3(episode['audio_url'], filename)
chunks = split_audio(filename)
full_transcript = ""
for chunk in chunks:
transcript = transcribe_audio(client, chunk)
full_transcript += transcript + " "
os.remove(chunk)
classification = classify_episode(client, episode['title'])
guest_name = episode['title'].split('with')[-1].strip() if 'with' in episode['title'] else "Guest"
labeled_transcript = label_speakers(client, full_transcript, guest_name)
summary_and_insights = generate_summary_and_insights(client, labeled_transcript, guest_name)
episode['transcript'] = labeled_transcript
episode['classification'] = classification
episode['summary_and_insights'] = summary_and_insights
os.remove(filename)
# Write the processed episode to BigQuery
write_to_bigquery(episode)
return episode
def main(feed_url, num_episodes):
client = openai.OpenAI(api_key='<YOUR_OPENAI_API_KEY')
# Ensure the BigQuery table exists
ensure_table_exists()
episodes = process_podcast(feed_url)[:num_episodes]
processed_episodes = []
for episode in episodes:
processed_episode = process_episode(client, episode)
processed_episodes.append(processed_episode)
check_table_rows()
return f"Processed {len(processed_episodes)} episodes and wrote them to BigQuery"
# Example usage
feed_url = "https://www.rittmananalytics.com/drilltodetail?format=rss"
num_episodes = 125
result = main(feed_url, num_episodes)
print(result)
After each episode is transcribed, we take that transcription and then pass it back to the OpenAI LLM to classify the episode using one primary, and multiple secondary, tag values.
def classify_episode(client, title):
prompt = f"""
Classify the following podcast episode title into the most relevant category and provide additional tags.
Use only the categories and tags provided below. Choose one primary tag and multiple secondary tags if applicable.
Title: {title}
Categories and Tags:
* Data Analytics 1.1. Business Intelligence 1.1.1. Dashboards 1.1.1.1. Interactive Dashboards 1.1.1.2. KPI Dashboards 1.1.2. Reporting Tools 1.1.2.1. Looker 1.1.2.2. Lightdash 1.2. Advanced Analytics 1.2.1. Customer Analytics 1.2.1.1. Customer Segmentation 1.2.1.2. Customer Journey Analysis 1.2.2. Marketing Analytics 1.2.2.1. Attribution Modeling 1.2.2.2. Ad Spend Analysis 1.2.3. Financial Analytics 1.2.3.1. Benchmarking 1.2.3.2. Forecasting 1.3. Web and Digital Analytics 1.3.1. Event-Based Analytics 1.3.2. SEO Analytics 1.4. Specialized Analytics 1.4.1. IoT Analytics 1.4.1.1. Smart Home 1.4.1.2. Smart Buildings 1.4.2. Media Analytics
* Data Strategy 2.1. Modern Data Stack 2.1.1. Components 2.1.1.1. Data Integration Tools 2.1.1.2. Data Transformation Tools 2.1.2. Best Practices 2.1.2.1. Project Management 2.1.2.2. Healthchecks 2.2. Data Governance 2.2.1. Data Quality 2.2.2. Data Lineage 2.3. Cloud Strategy 2.3.1. Google Cloud 2.3.2. Oracle Cloud 2.3.3. Multi-Cloud Solutions
* Data Centralization 3.1. Data Warehousing 3.1.1. Cloud Data Warehouses 3.1.1.1. BigQuery 3.1.1.2. Autonomous Data Warehouse 3.1.2. Data Lakehouses 3.2. Data Modeling 3.2.1. Semantic Layers 3.2.2. Dimensional Modeling 3.2.2.1. Slowly Changing Dimensions 3.3. Data Engineering 3.3.1. ETL and Data Pipelines 3.3.2. Data Transformation 3.3.2.1. dbt 3.4. Data Integration 3.4.1. Customer Data Platforms 3.4.2. Data Synchronization
* Artificial Intelligence 4.1. Machine Learning 4.1.1. Predictive Analytics 4.1.2. Customer Lifetime Value 4.2. Natural Language Processing 4.2.1. Text Generation 4.2.2. Sentiment Analysis 4.3. Generative AI 4.3.1. Large Language Models 4.3.2. AI-Powered Chatbots 4.4. AI in Business Intelligence 4.4.1. Automated Insights 4.4.2. AI-Enhanced Dashboards
Output format:
Primary Tag: [Single most relevant tag]
Secondary Tags: [Comma-separated list of additional relevant tags]
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a podcast classification assistant."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
We then create another LLM prompt that, with the guest name added as function parameter too, summarises the episode contents, extracts three key insights or trends from the episode together with three notable quotes from the episode guest.
def generate_summary_and_insights(client, transcript, guest_name):
prompt = f"""
Analyze the following podcast transcript and provide a summary of the key insights, opinions, and analytics industry trends discussed. Also, identify and quote 2-3 insightful or interesting statements made by the guest speaker, {guest_name}.
Format your response as follows:
Summary: [A concise summary of the main points discussed in the podcast, focusing on insights, opinions, and industry trends]
Key Insights:
1. [First key insight or trend]
2. [Second key insight or trend]
3. [Third key insight or trend]
Notable Quotes:
1. "{{First quote}}" - {guest_name}
2. "{{Second quote}}" - {guest_name}
3. "{{Third quote}}" - {guest_name} (if available)
Transcript:
{transcript}
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are an AI assistant specialized in analyzing data analytics and business intelligence podcasts."},
{"role": "user", "content": prompt}
],
max_tokens=1000
)
return response.choices[0].message.content
As the raw Whisper API transcription output doesn’t distinguish between speakers, this function splits the transcription up into individual sentences and asks the LLM to try and assign those sentences to myself and the episode guest based on who logically should be saying what at various points.
def label_speakers(client, transcript, guest_name):
def split_transcript(transcript, max_chunk_size=3000):
words = transcript.split()
chunks = []
current_chunk = []
current_size = 0
for word in words:
if current_size + len(word) + 1 > max_chunk_size:
chunks.append(' '.join(current_chunk))
current_chunk = [word]
current_size = len(word)
else:
current_chunk.append(word)
current_size += len(word) + 1
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
chunks = split_transcript(transcript)
labeled_chunks = []
for i, chunk in enumerate(chunks):
prompt = f"""
Label the following chunk of podcast transcript with speaker names. The host is Mark Rittman, and the guest is {guest_name}.
Format the output as:
Mark Rittman: [Speaker's words]
{guest_name}: [Speaker's words]
Use your understanding of conversation flow and context to accurately label each part of the dialogue.
If you're unsure about a speaker, use your best judgment based on the content and style of speech.
This is chunk {i+1} of {len(chunks)}. Maintain consistency with previous chunks if applicable.
Transcript chunk:
{chunk}
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a transcript labeling assistant."},
{"role": "user", "content": prompt}
]
)
labeled_chunks.append(response.choices[0].message.content)
return "\n".join(labeled_chunks)
The transcription and all of the additional insights we’ve derived are written to a Google BigQuery table and dataset.
# Define the schema for your BigQuery table
schema = [
bigquery.SchemaField("title", "STRING", mode="REQUIRED"),
bigquery.SchemaField("link", "STRING"),
bigquery.SchemaField("description", "STRING"),
bigquery.SchemaField("published", "STRING"),
bigquery.SchemaField("audio_url", "STRING"),
bigquery.SchemaField("transcript", "STRING"),
bigquery.SchemaField("classification", "STRING"),
bigquery.SchemaField("summary_and_insights", "STRING"), # New field
]
def ensure_table_exists():
dataset_ref = bq_client.dataset(dataset_name)
table_ref = dataset_ref.table(table_name)
try:
bq_client.get_table(table_ref)
except Exception:
table = bigquery.Table(table_ref, schema=schema)
table = bq_client.create_table(table)
print(f"Created table {table.project}.{table.dataset_id}.{table.table_id}")
def write_to_bigquery(episode):
# Ensure the table exists
ensure_table_exists()
# Prepare the data for BigQuery
row = {
'title': episode['title'],
'link': episode.get('link', ''),
'description': episode.get('description', '')[:1024], # Truncate description if it's too long
'published': episode.get('published', ''),
'audio_url': episode.get('audio_url', ''),
'transcript': episode.get('transcript', '')[:1048576], # Truncate transcript if it's too long (1MB limit)
'classification': episode.get('classification', ''),
'summary_and_insights': episode.get('summary_and_insights', '')[:1048576] # New field, also truncated if necessary
}
# Get the table reference
table_ref = bq_client.dataset(dataset_name).table(table_name)
# Load the data into BigQuery
try:
errors = bq_client.insert_rows_json(table_ref, [row])
if errors == []:
print(f"Episode '{episode['title']}' successfully written to BigQuery")
else:
print(f"Errors occurred while writing episode '{episode['title']}' to BigQuery: {errors}")
print(f"Problematic row: {row}")
except google_exceptions.BadRequest as e:
print(f"BadRequest error for episode '{episode['title']}': {e}")
print(f"Problematic row: {row}")
except Exception as e:
print(f"Unexpected error for episode '{episode['title']}': {e}")
print(f"Problematic row: {row}")
# Add this function to check if rows were actually inserted
def check_table_rows():
query = f"""
SELECT COUNT(*) as row_count
FROM `{bq_client.project}.{dataset_name}.{table_name}`
"""
query_job = bq_client.query(query)
results = query_job.result()
for row in results:
print(f"Number of rows in the table: {row.row_count}")
Viewing the resulting BigQuery table we can see the episode transcripts along with all the other derived data and episode metadata.

And finally the BigQuery dataset then becomes the data source for the https://podcasts.rittmananalytics.com web application, with the screenshot below showing an example episode transcript.
INTERESTED? FIND OUT MORE!
Rittman Analytics is a boutique data analytics consultancy that helps ambitious, digital-native businesses scale-up their approach to data, analytics and generative AI.
We’re authorised delivery partners for Google Cloud along with Oracle, Segment, Cube, Dagster, Preset, dbt Labs and Fivetran and are experts at helping you design an analytics solution that’s right for your organisation’s needs, use-cases and budget and working with you and your data team to successfully implement it.
If you’re looking for some help and assistance with your AI initiative or would just like to talk shop and share ideas and thoughts on what’s going on in your organisation and the wider data analytics world, contact us now to organise a 100%-free, no-obligation call — we’d love to hear from you!
Recommended Posts
Drill to Detail Podcast Transcripts & Gen AI Insights Now Available, Powered by OpenAI Whisper API & BigQuery Colab Notebooks
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
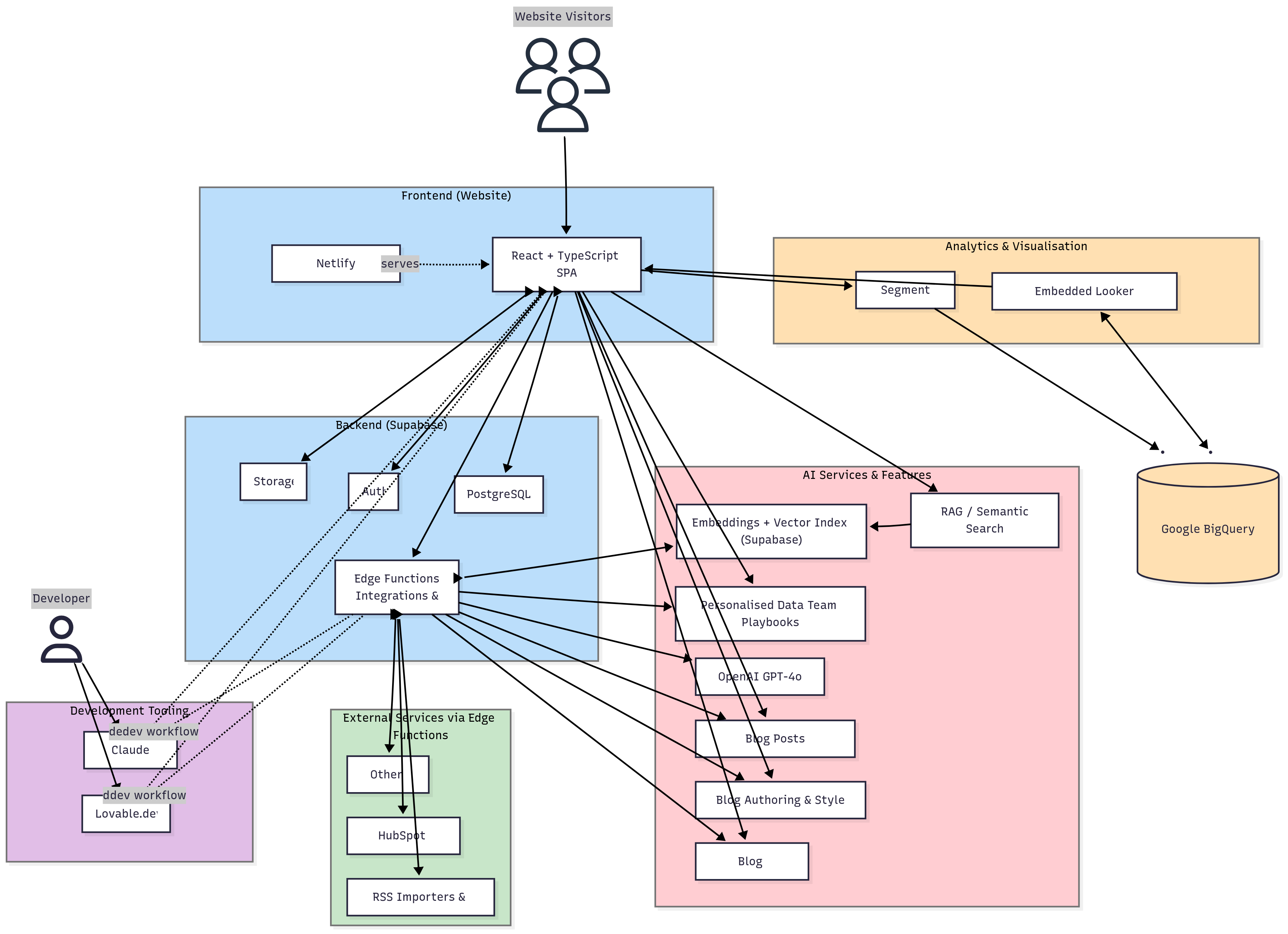
Opinionated, AI-Enabled & Modern: The Story Behind Rittman Analytics’ New Website
