Creating a Self-Learning Data Analytics SQL Chatbot using LangChain, RAG, Open AI and Google BigQuery Vector Store
In previous articles on this blog I’ve talked about Creating a Conversational Data Analyst Chatbot using LangChain, OpenAI, Google BigQuery and Google Cloud Functions and more recently, How Rittman Analytics Automates our Profit & Loss Reporting and Commentary using VertexAI Gemini 1.5-FLASH and Google BigQuery.
The former of showed how we could create a chatbot that could dynamically create and run SQL queries, with the latter showing how we could pre-create analysis of a report for display and use later.
In this article we’ll combine these two generative AI use-cases to create a prototype of a data analyst chatbot that can source from pre-created or dynamically-retrieved report data, and can learn and improve the quality of its responses by leveraging Google BigQuery Vector Store to store for later reference successful answers to user questions in the past.

The code for the notebook used to create the prototype is available on Github, and the P&L report analysis that we load into BigQuery Vector Store was created using another BigQuery notebook also using LLMs and Langchain, a version of which can be found here.
As always, if you’re interested in getting some help for you and your team on use-cases like this one, schedule a free, no-obligation call now and we can have an informal chat about this and other Gen AI use-cases we’ve helped our clients with.
Google BigQuery Vector Search and Vector Store
Google BigQuery Vector Store is a fully managed service that allows users to efficiently store and query vector embeddings within Google BigQuery. By integrating directly into BigQuery, the vector store leverages BigQuery’s scalability, performance, and robust security infrastructure, offering a cost-effective solution for managing massive vector datasets.
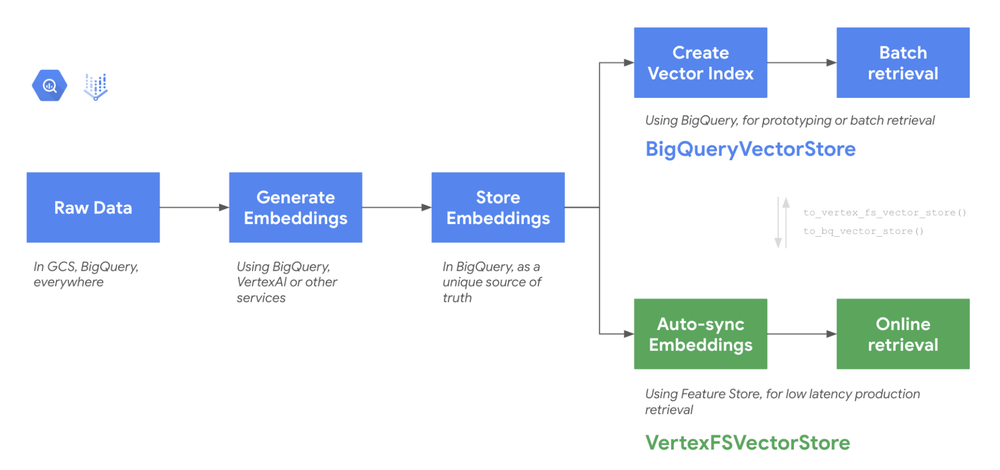
LangChain provides a higher-level abstraction for interacting with the BigQuery Vector Store, simplifying the process of embedding generation, vector storage, and similarity search. LangChain handles the embedding generation (using pre-trained models), uploading vectors to the BigQuery table, and performing similarity searches based on the chosen distance metric.
What Technology Does This Gen AI Solution Use?
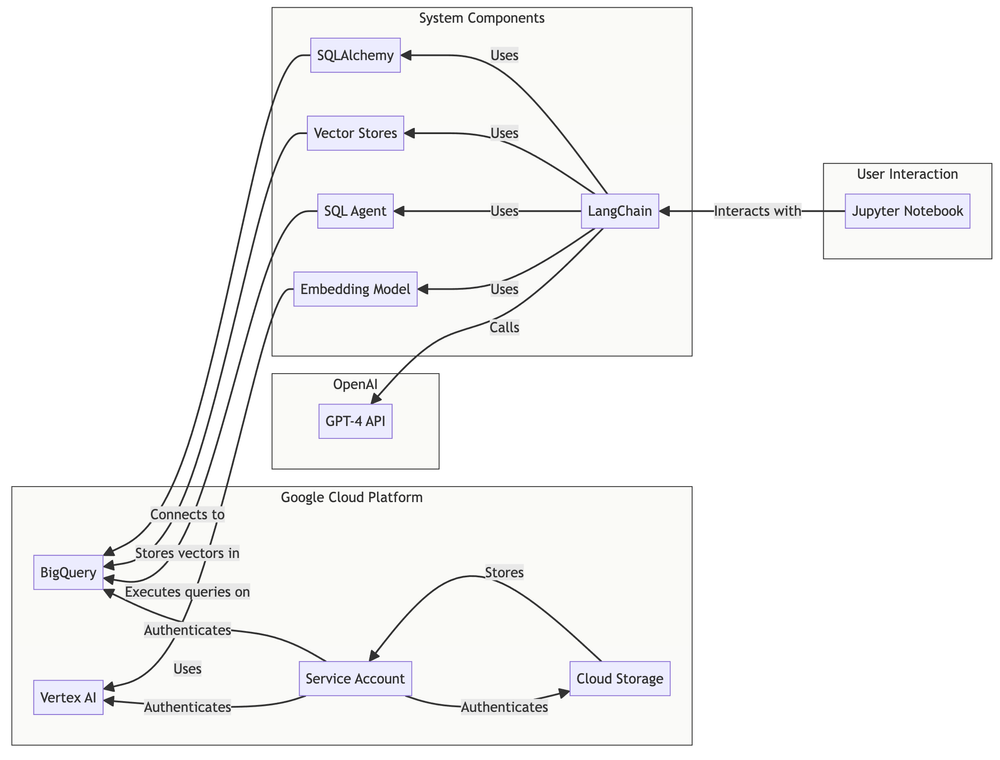
The generative AI example used for this use-case was written in Python and, for development purposes, run in a Google BigQuery python notebook. The diagram below shows the key components and how they interact with each other in order to answer questions entered by the user.
-
Data Source (BigQuery): The P&L data resides in BigQuery, organized into tables like
pl_reports,profit_and_loss_report_account_group, etc. -
Vector Store (BigQuery): A BigQueryVectorStore table is used to store embeddings of pre-created P&L analysis texts, as shown in the SQL example below. This allows for efficient similarity search to quickly find relevant context for user questions. The table
pl_reports_vector_storageholds these embeddings. A separate vector store,successful_qa_pairs, is used to store successful question-answer pairs for learning and improving the system's performance. -
LLM (OpenAI’s GPT-4): The core intelligence is provided by OpenAI’s GPT-4, acting as the question answering engine, deciding how likely it would be that the pre-created analysis would answer the question and providing natural language processing capabilities.
-
Langchain: Langchain orchestrates the interaction between the different components. It manages the agent, memory, chains, and toolkits to provide a cohesive and efficient workflow.
-
SQL Agent (Langchain): An SQL agent is used to directly query BigQuery when the vector store does not contain sufficient information to answer a question.
-
Embedding Model (Vertex AI):
textembedding-gecko@latestfrom Google Vertex AI creates vector embeddings of text data, enabling semantic search within the vector store to try and find successful examples of answers to similar questions we can use to fine-tune the user’s query.
# Create a BigQuery client
client = bigquery.Client.from_service_account_json(service_account_file)
# Initialize embedding model
embedding_model = VertexAIEmbeddings(
model_name="textembedding-gecko@latest",
project=project
)
# Initialize BigQueryVectorStore containing P&L report analysis texts
vector_store = BigQueryVectorStore(
project_id=project,
dataset_name=dataset,
table_name="pl_reports_vector_storage",
location=location,
embedding=embedding_model,
)
def load_vector_storage():
query = f"""
SELECT date_month as month, COALESCE(report_analysis, '') || COALESCE(invoice_analysis, '') || COALESCE(recurring_payments_analysis, '') as content
FROM `{project}.{dataset}.pl_reports`
"""
df = client.query(query).to_dataframe()
for _, row in df.iterrows():
month = row['month']
text = row['content']
metadata = {'month': month} # Removed analysis_type as it's no longer needed
vector_store.add_texts([text], metadatas=[metadata])
print("Vector storage loaded successfully.")
# Initialize embedding model
embedding_model = VertexAIEmbeddings(
model_name="textembedding-gecko@latest",
project=project
)
def get_similar_qa(question: str, k: int = 3):
"""Retrieve similar Q&A pairs from the vector store."""
print(f"Searching for similar Q&A pairs to: {question}")
similar_qa = qa_vector_store.similarity_search(question, k=k)
print(f"Retrieved {len(similar_qa)} similar Q&A pairs")
converted_results = []
for i, item in enumerate(similar_qa):
if isinstance(item, Document):
converted_results.append(item)
print(f"Document {i+1} (already Document):")
print(f" Page content: {item.page_content[:100]}...")
print(f" Metadata: {item.metadata}")
else:
# Handle cases where the item might be a dict or have a different structure
text = item.get('text', item.get('page_content', ''))
metadata = {key: value for key, value in item.items() if key not in ['text', 'page_content']}
doc = Document(page_content=text, metadata=metadata)
converted_results.append(doc)
print(f"Document {i+1} (converted to Document):")
print(f" Page content: {text[:100]}...")
print(f" Metadata: {metadata}")
return converted_results
So How Does the Chatbot Answer User’s Questions (and Learn from User Feedback?
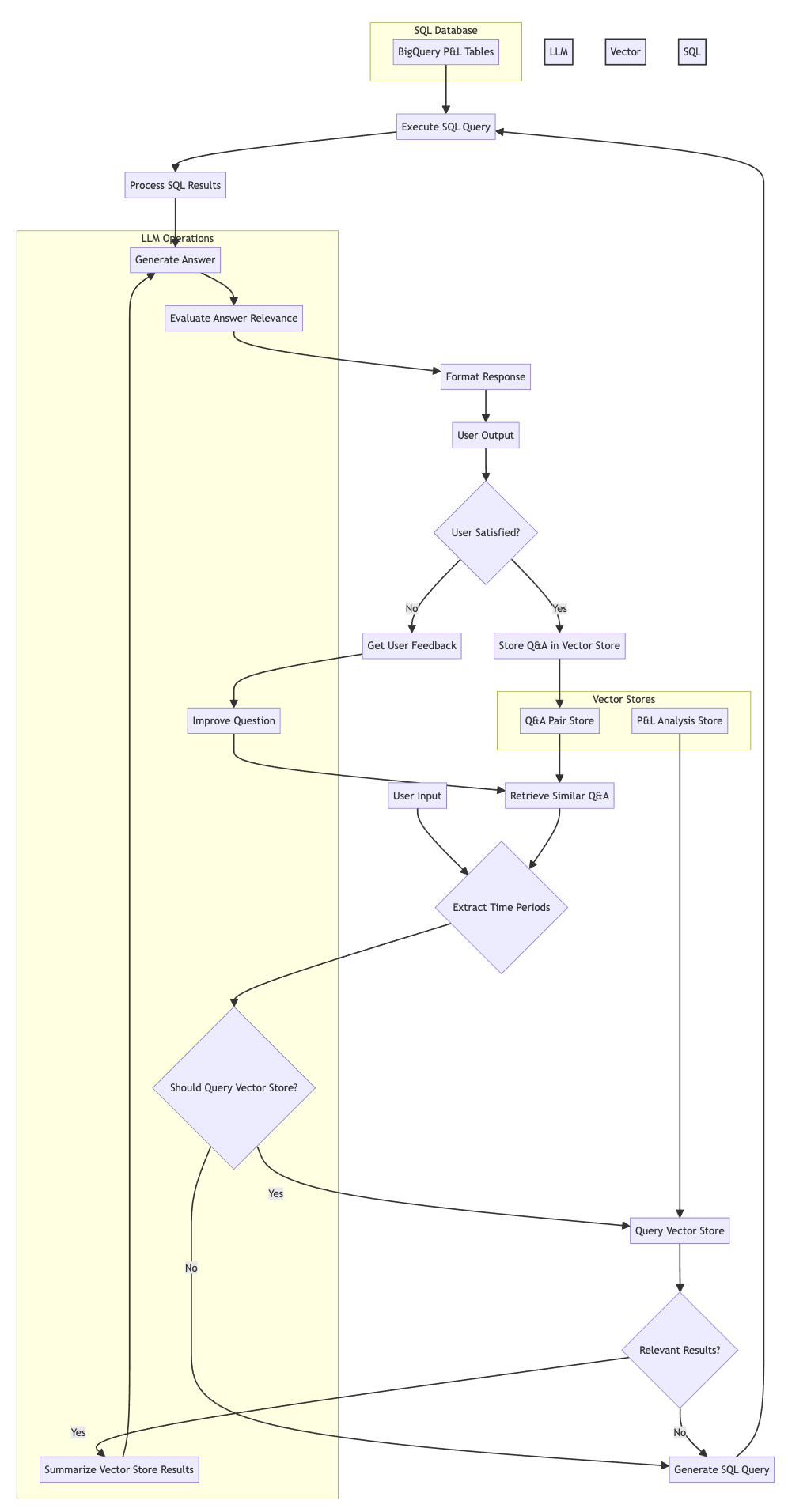
So how do these components and data stores come-together to answer the user’s query? The process of answering a question follows the steps illustrated by the diagram below:
-
Question Analysis: The user enters a natural language question.
-
Vector Store Query (First Attempt): The system determines whether the question can be answered using the pre-created analysis stored in the
pl_reports_vector_storagevector store. This is determined by a prompt sent to the LLM, evaluating if the question aligns with the types of analyses performed and the available time range. If deemed suitable, a similarity search is performed to retrieve the most relevant document(s). -
Pre-created Answer Summarization: If relevant documents are found, their content is extracted, stripped of HTML tags, and summarized using the LLM to focus only on information relevant to the question. This avoids providing irrelevant information from the original analysis.
-
SQL Query (Fallback): If the vector store query does not yield satisfactory results or is deemed unsuitable, the system uses the Langchain SQL agent. This component uses the LLM to (i) analyze the question to identify relevant financial terms and entities, (ii) translate these terms into a suitable SQL
WHEREclause to filter the data (iii) construct a SQL query to the appropriate BigQuery table (profit_and_loss_report_account_group_xa,profit_and_loss_report_sub_categories_xa, orprofit_and_loss_report_categories_xadepending on the question context) and (iv) execute the query in BigQuery and format the results into a readable answer. -
Answer Relevance Evaluation: The generated answer (whether from the vector store or SQL query) is evaluated by the LLM to assess its relevance to the original question and provides a relevance score and explanation.
-
Feedback and Learning: The user provides feedback on the answer. This feedback is used to improve the question for subsequent iterations, aiming to refine the answer. Successful question-answer pairs are stored in the
successful_qa_pairsvector store, improving future responses. -
Iterative Refinement (Optional): The system allows for iterative refinement based on user feedback. The LLM is used to reformulate the question in response to feedback, repeating the process for
max_iterations(default 3).
INTERESTED? FIND OUT MORE!
Rittman Analytics is a boutique data analytics consultancy that helps ambitious, digital-native businesses scale-up their approach to data, analytics and generative AI.
We’re authorised delivery partners for Google Cloud along with Oracle, Segment, Cube, Dagster, Preset, dbt Labs and Fivetran and are experts at helping you design an analytics solution that’s right for your organisation’s needs, use-cases and budget and working with you and your data team to successfully implement it.
If you’re looking for some help and assistance with your AI initiative or would just like to talk shop and share ideas and thoughts on what’s going on in your organisation and the wider data analytics world, contact us now to organise a 100%-free, no-obligation call — we’d love to hear from you!
Recommended Posts
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
