Data Lakehouses, Post-Modern Data Stacks and Enabling Gen AI: The Rittman Analytics Guide to Modernising Data Analytics in 2024 — Rittman Analytics
Are you the data lead for a business that’s recently outgrown the mess of data extracts and Google Sheets you use to analyze and understand your performance today, and realise its time to move to something more robust, scalable and trustworthy for the future?
Or maybe you’re looking to modernise your existing data platform and make the move to the cloud, migrating from legacy on-premises to cloud technology and hoping to increase your data team’s agility while maintaining the same levels of security, management and governance that you have now.
Modernising your BI and data analytics platform is all about leveraging the increased agility, scalability and user-friendliness of modern cloud technology to better align your organisation’s data capabilities with the needs of your users.
But where do you start and what does the technology landscape look like today?
In this blog I’ll answer two of the most common questions my team gets asked by organisations looking to modernise and scale-up their data stack in 2024:
-
Whether its your first data analytics project or a bid to modernise your existing analytics capability, what do you need to consider when planning a data analytics project and what goes into a succcessful business case?
-
And what are the typical components in a “post-modern” data stack that we’d deploy for clients today, one that balances modern, composable cloud-hosted technology with the security and management needs of larger, more mature organisations?
Planning your Data Analytics or Data Modernisation Project
With the days of cheap money long behind us, it’s safe to assume that any funding request for a data analytics or BI modernisation project has got to come with a pretty convincing and bullet-proof business case.
To have any real chance of approval your project plan and business case needs to show you’ve considered and have answers for challenges such as:

-
What you hope to achieve with your data centralization and modernisation project, the key business questions you want to answer and the the problems you’ll be solving for your business
-
What are the clear, measurable objectives you’ll work towards that align with your company’s strategy and deliver or enable real growth in revenue, customer satisfaction and increased business efficiency
-
How you’ve made sure you’ve surveyed and understood what capabilities your organization already has and why and how these fall-short of what’s needed today
-
How you plan to identify and work with stakeholders, identify risks that could delay or threaten delivery of the project and develop a comprehensive change management plan to ensure your business gets the maximum value from the investment you’re asking for
-
And crucially … how the investment you’re asking for will deliver value to the business and your project sponsor within, at most, six to nine months given the typical twelve-month budgeting cycle
Think you’re ready and have this all-planned? Take our Data Analytics Project Planning Quiz and receive a free, comprehensive scorecard telling you where you’ve got things covered and where your planning falls short.
Or if you’re just at the planning stage now and would like some tips on what needs to be considered then our free Data Analytics Project Planning Checklist is essential reading — and we’ve even provided an example Data Analytics Project business case in PDF and MS Word format to give you an example of “good” looks like and is likely to get approval for funding.
And, of course, we can help you scope-out and create a comprehensive plan for your data analytics or data stack modernisation project - check-out our Project Discovery service for more details.
Data Warehouses become Data Lakehouses
Congratulations! You’ve had your business case approved with just about enough detail about how you’re going to actually do it — so what does a modern data stack look like these days?
At a fundamental level, if you drew a high-level diagram of a modern, best-of-breed data stack today it would look like the diagram below that has three main parts to it:
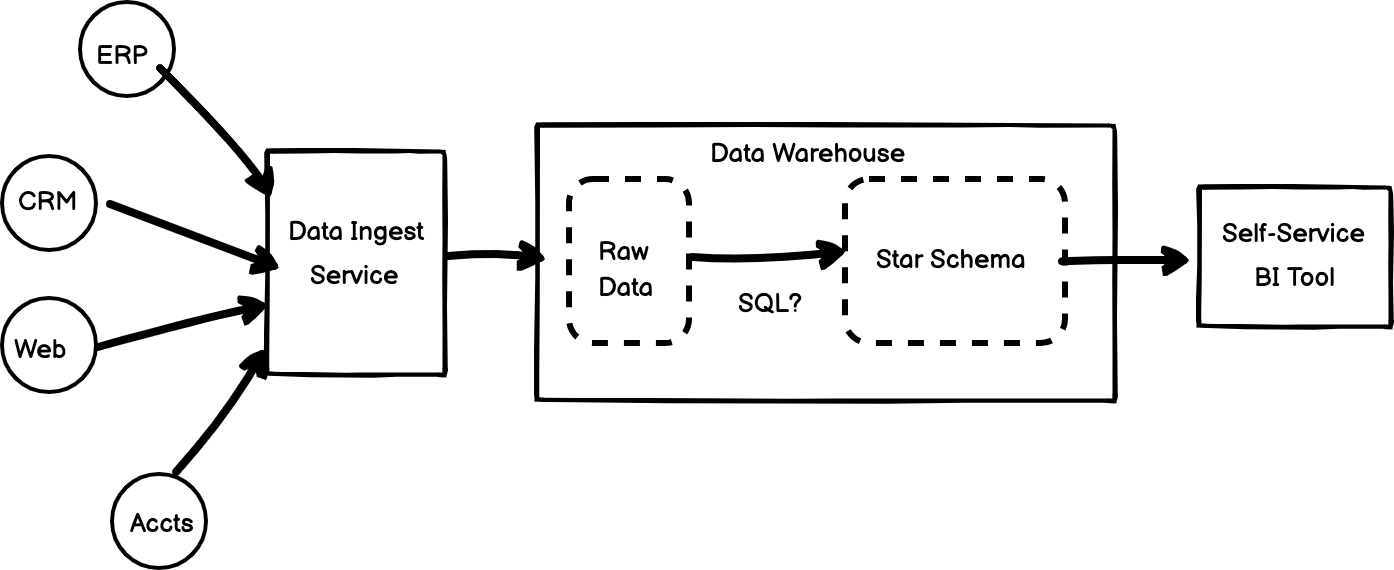
-
A data ingestion service that connects to and extracts the data you need from the applications, databases and websites that hold the data used to run your business
-
A data warehouse database typically provided as a fully-managed service by one of the big cloud vendors, for example Google Cloud, so that you don’t have to buy servers and hire DBAs to tell you that none of the backups would restore and no-ones ever tested them anyway
-
A self-service BI tool that’s designed to let business users get access to the data they need without having to ask IT to build reports for them
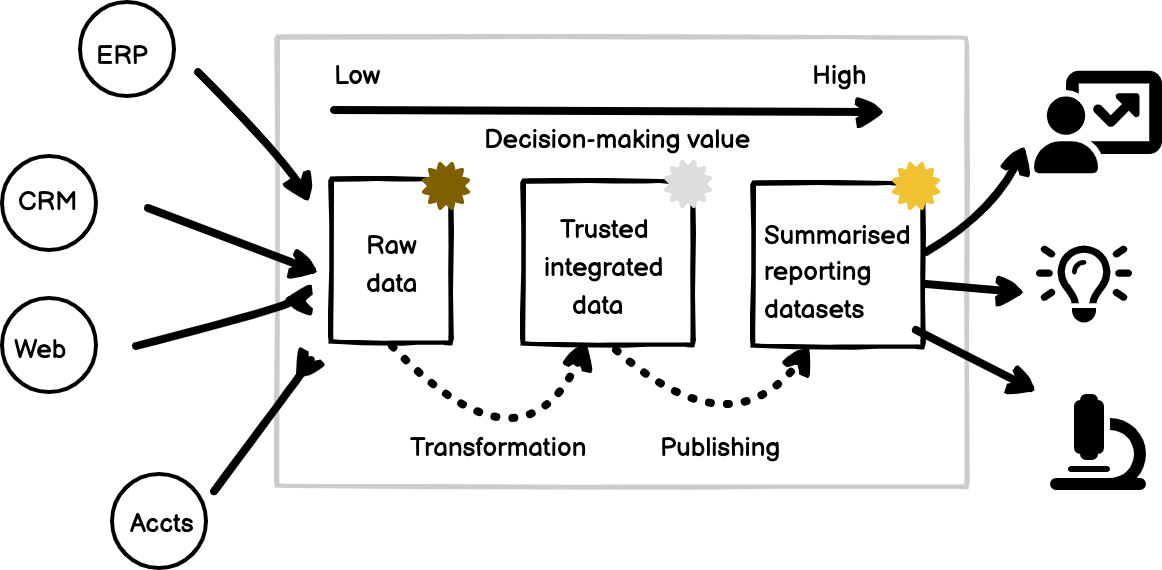
The data warehouse is where data goes from its raw and source-specific form through an intermediate stage where its standardised in structure, joined and cleansed and then made ready for analysis typically in the form of a facts-and-dimensions star schema.
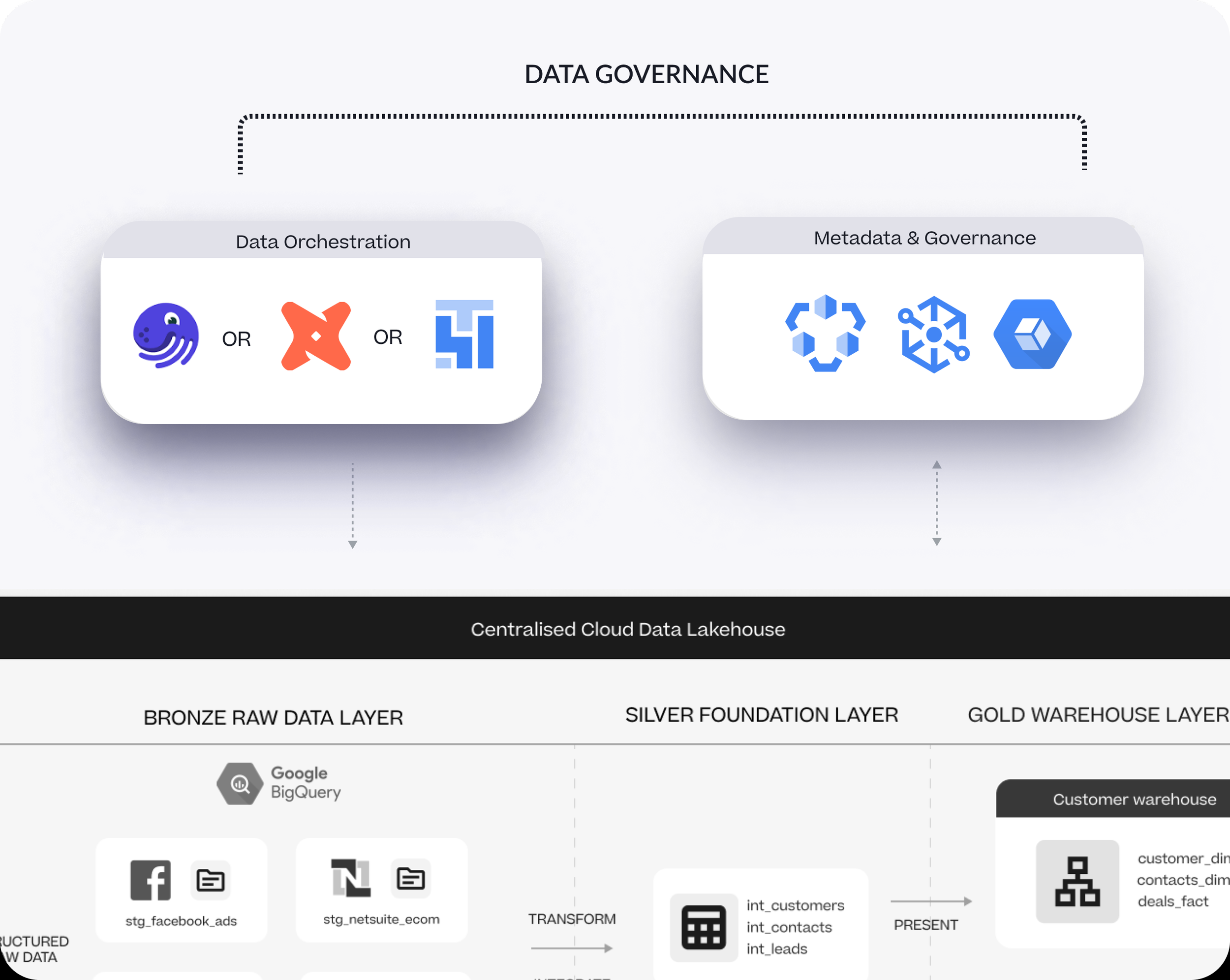
The current name for this type of setup is a “medallion architecture” with bronze silver and gold layers for indicating the reporting trustworthiness of the raw, intermediate and presentation layers of the warehouse.
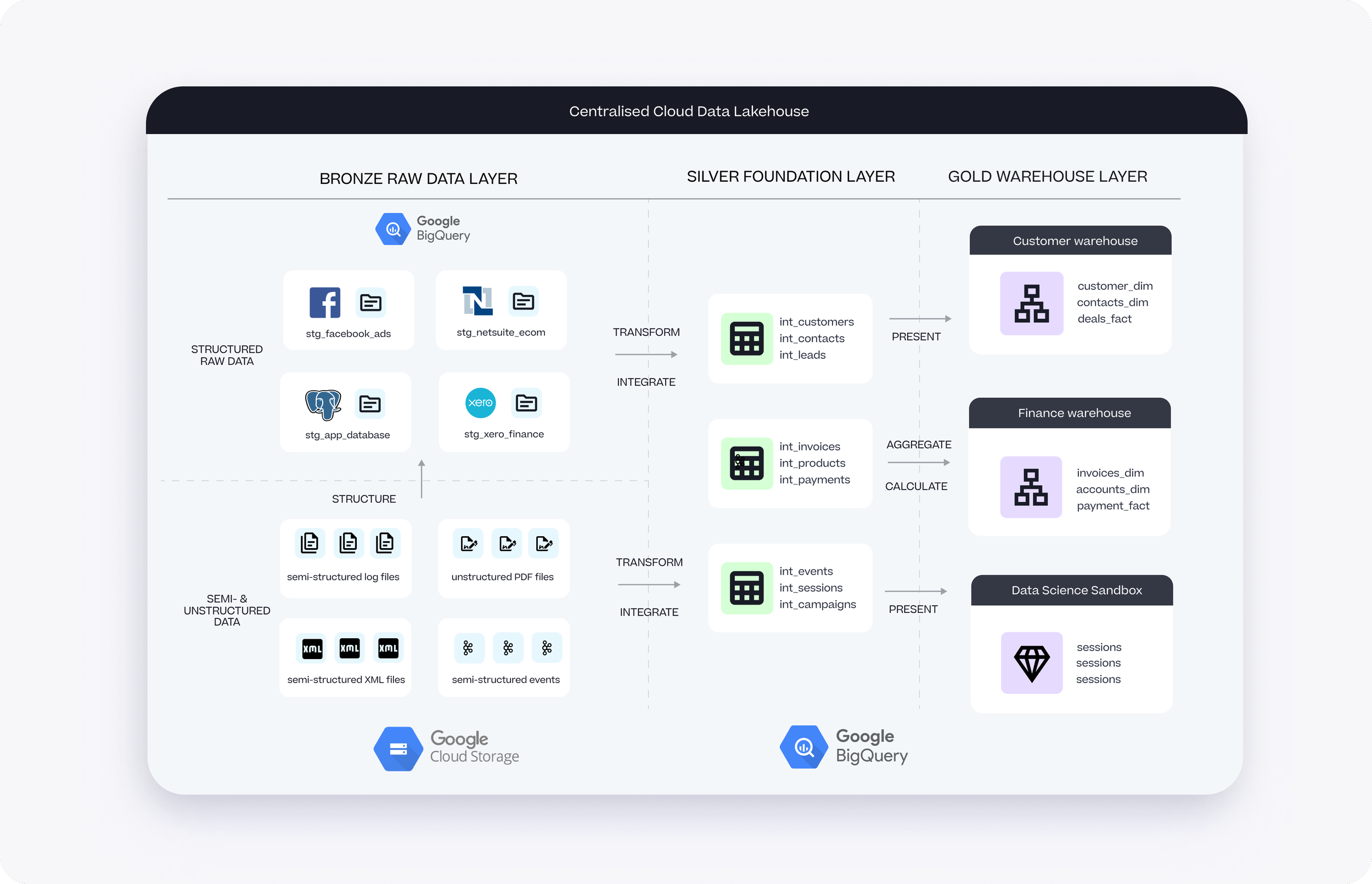
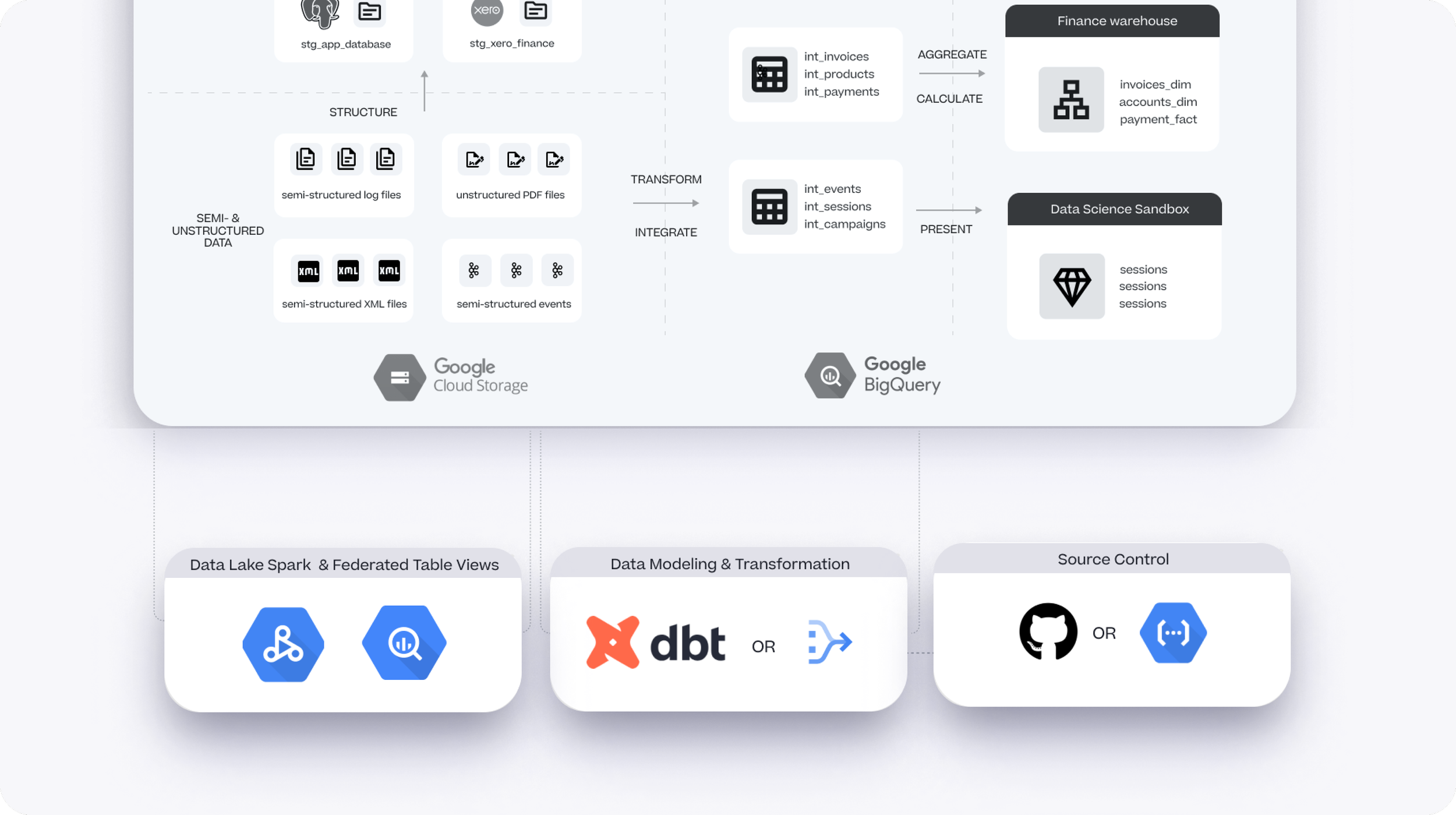
Fast-forward to today and a typical modern data warehouse platform is more accurately described as a “data lakehouse”, an architecture that extends the warehouse’s traditional relational storage capabilities to now incorporate cheap, flexible object storage.
This type of storage is ideal for storing the semi-structured and unstructured datasets that data scientists prefer, and by using Google BigQuery for example together with BigLake and Google Cloud Storage you can present all of these different datatypes as a single unified warehouse environment.
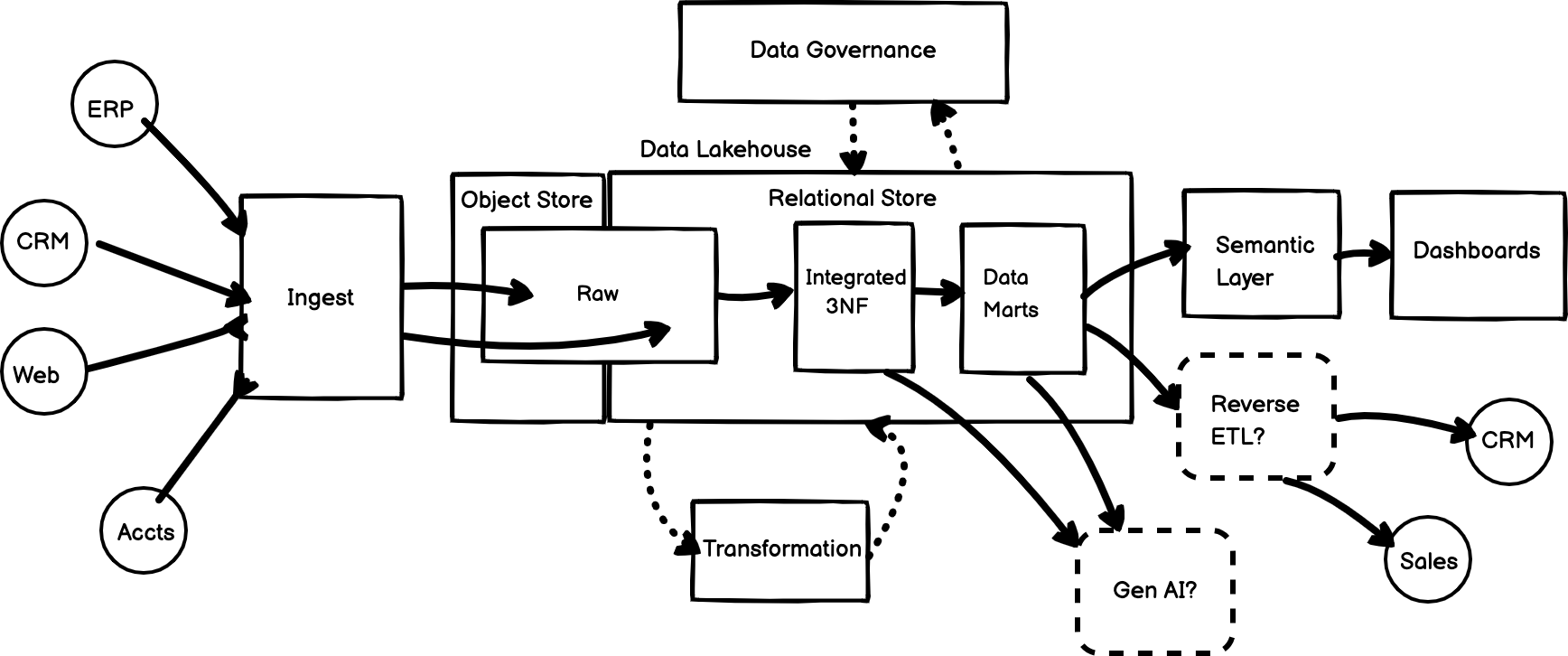
The Post-Modern Data Stack
Today’s cloud data warehouse or data lakehouse is the core foundation of what’s termed the “modern data stack”, defined as a set of composable (replaceable, plug-in compatible) best-of-breed components typically from a number of different vendors that provide you with:
-
The ability to ingest not just traditional application and database data using batch and now real-time loading, along with event data from web and mobile sources as well as Kafka and message buses
-
Dedicated services for modeling and transforming your data and orchestrating its lifecycle in the form of “software defined assets”
-
A semantic layer that provides for business users a layer of abstraction over the data in your warehouse as well as caching, access control and APIs to enable embedding within your user-facing applications
-
Catalogs for the metadata generated by all your data warehousing activity and making that information available to users from a single, centralised location so that they can, for example, track the lineage of their reporting data and understand what sources and what transformations were applied to the data before they see it in their reporting tool
-
ML and Gen AI models integration that can take the complete customer profiles you now generate from centralising all your customer interaction points in you cloud data warehouse along with risk and propensity scores you’re now able to calculate, and feed that into your CRM and marketing platforms using what’s referred to now as “reverse ETL” tools
-
And last but certainly not least, a platform for taking this integrated, trusted and well-labelled centralised dataset and using it as training and search augmentation data for LLMs (large language models), the use-case that we’re finding is generating the most interest for our clients these days
Putting all of this together and assigning actual products and services to the various components gives us the platform architecture in the diagram below that we recommend to organisations looking to scale-up and modernise their data analytics stack.
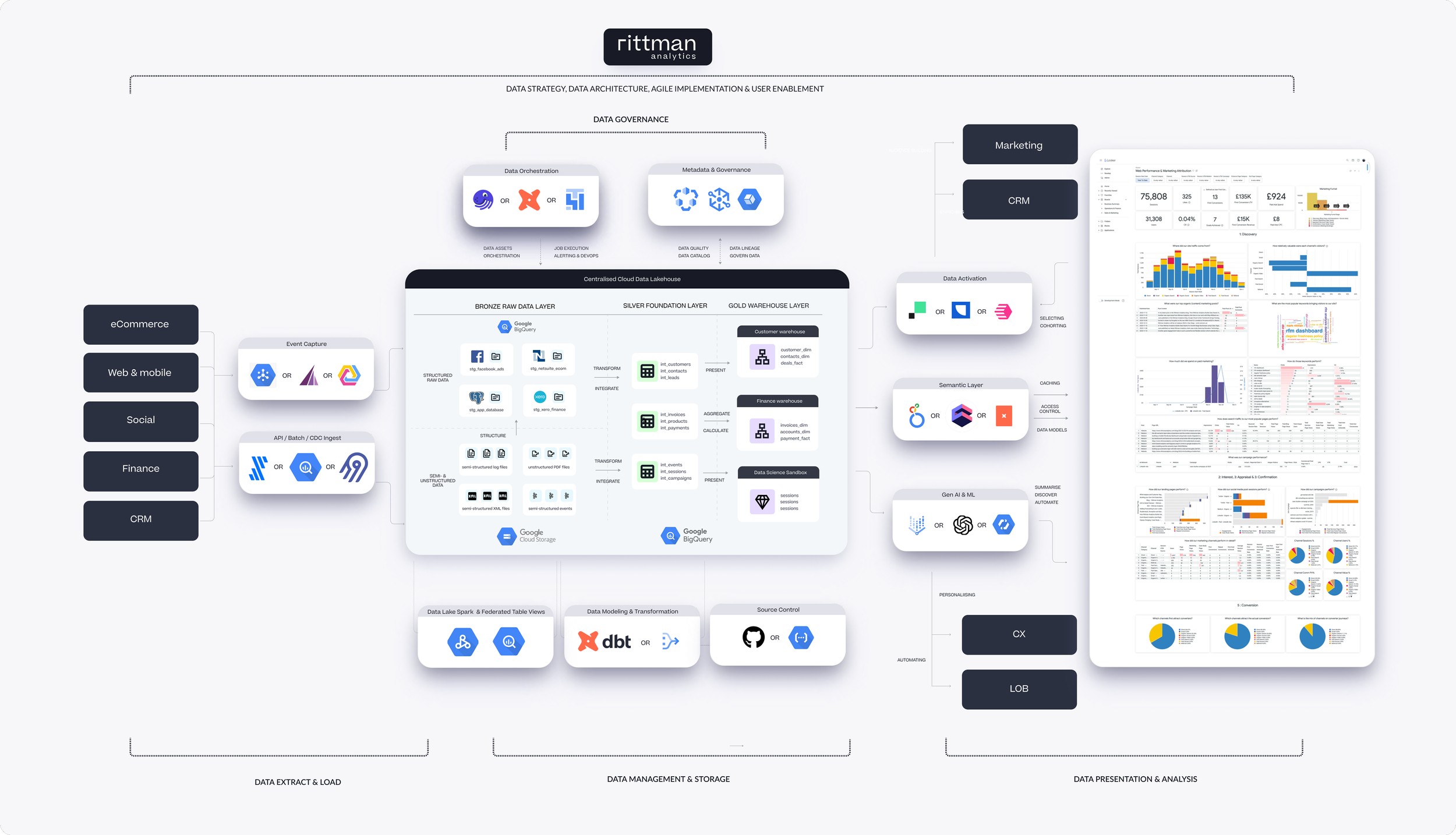
Many of the products and capabilities in this stack are established and long-running features of most of the client implementations we’ve delivered over the past five years, and we generally recommend Google Cloud as the cloud infrastructure foundation supplemented by specialist vendor services where they fill-in functionality that Google don’t yet offer (or just do the job better)
Data ingestion is a good example in that, whilst there are services such as Cloud Dataflow, PubSub and BigQuery Data Transfer Service that can automate the loading of data into your BigQuery warehouse, we typically recommend third-party services such as Fivetran and Airbyte as they’re more feature-complete than DTS and don’t require custom development as the other platform-native options do.

Segment and Rudderstack are great options for event collection with the latter typically cheaper than the former for B2C and D2C-type businesses, and more recently we’ve been closely following OpenSnowCat, the open-source fork of the formerly open-source but now “source-available” Snowplow.
Data transformation is well-handled by dbt Core, the open-source transformation and modeling toolkit that generates SQL and Python / Cloud Dataproc code to transform data between layers in your warehouse; we are however seeing uptake of Dataform (a transformation toolkit similar in functionality to dbt but more closely integrated with BigQuery and Google Cloud) incentivised by the fact that like dbt Core it’s free to use, but any associated running costs can be paid-for our of their Google Cloud commit rather than having to deal with yet another vendor.
The data warehouse, or “lakehouse” as I mentioned earlier is built on Google BigQuery along with Google Cloud Storage and a new service called BigLake to bring both types of storage together.
A new addition to certain of our data stacks and where this gets “post-modern” is in the addition of cloud services such as Google Cloud Dataplex that provide enterprise-class manageability, governance and a single pane-of-glass management that more mature and established clients migrating from the likes of Oracle and Teradata are typically looking for.
Last but not least, we still love Looker and given the choice we’d always recommend it as the best ad-hoc, developed-friendly data analytics service regardless of whether you’re using BigQuery, or Snowflake or any of the other cloud data warehouses it supports.
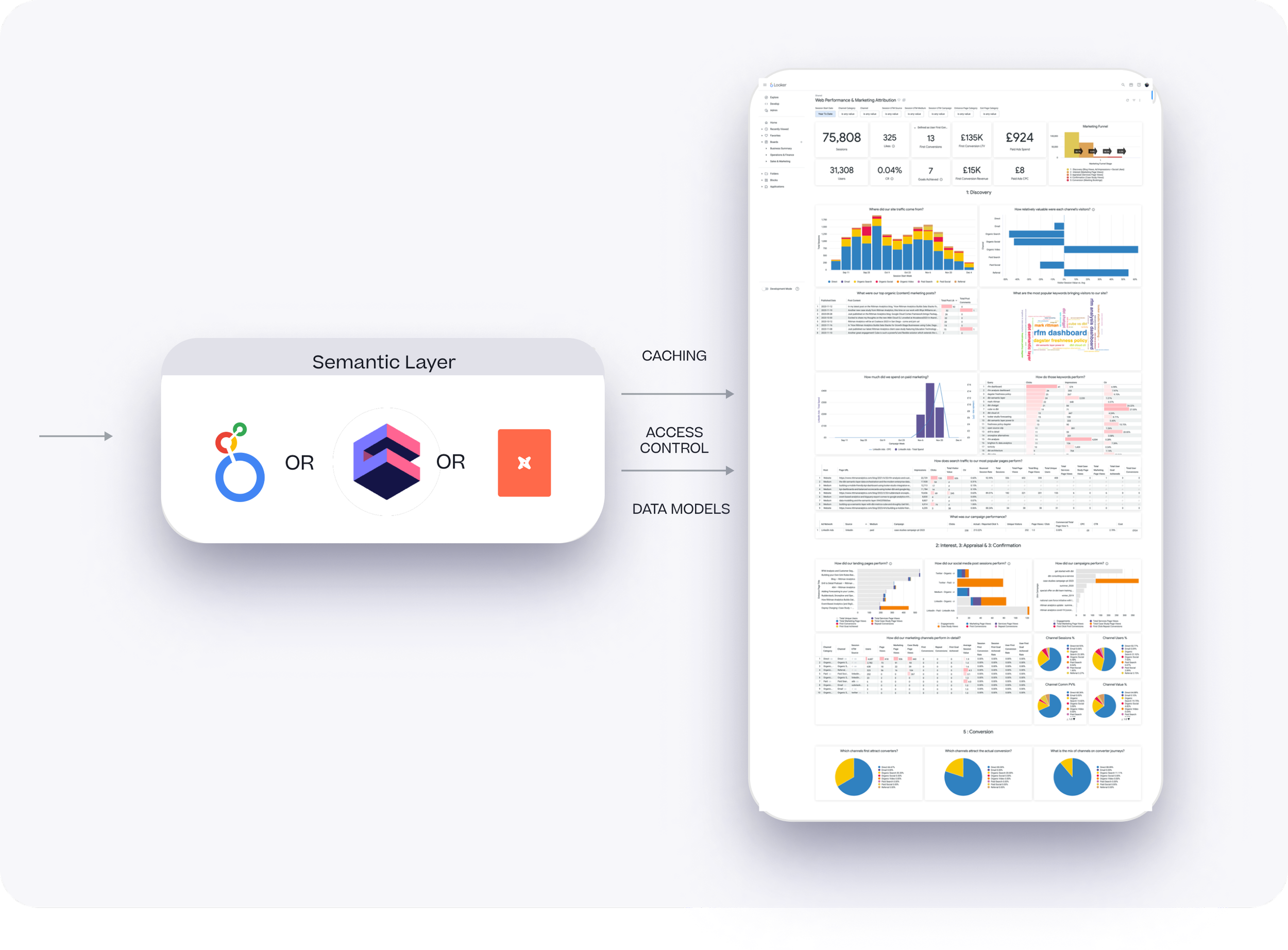
We’ve also got a huge, not-so-secret crush on Cube, the don’t-call-it-headless-BI open-source project and fully-managed commercial service that in many ways goes beyond even Looker’s LookML-based semantic model capabilities and adds really-smart caching, APIs for embedded analytics and integration with BI tools that was recently extended to cover Microsoft Power BI.
But Looker though, combined for example with Vertex AI, Google’s Gen AI platform, is showing the future of how dashboards and self-service analytics will look in the next few years, for example automating the creation of dashboard narratives and insights as well as lowering the barriers to data analytics access by enabling natural language querying of your business data
INTERESTED? FIND OUT MORE
Rittman Analytics is a Google Cloud Partner that specialises in data warehousing, data lakehouses and the modern data stack. We can help you you centralise your data sources, scale your data analytics capability and enable your end-users and data team with best practices and a modern analytics workflow.
If you’re looking for some help and assistance modernising your data stack and data warehouse and moving to a modern, flexible and modular Google Cloud data stack, contact us now to organize a 100%-free, no-obligation call — we’d love to hear from you and see how we can help make your data analytics vision a reality.
Recommended Posts
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
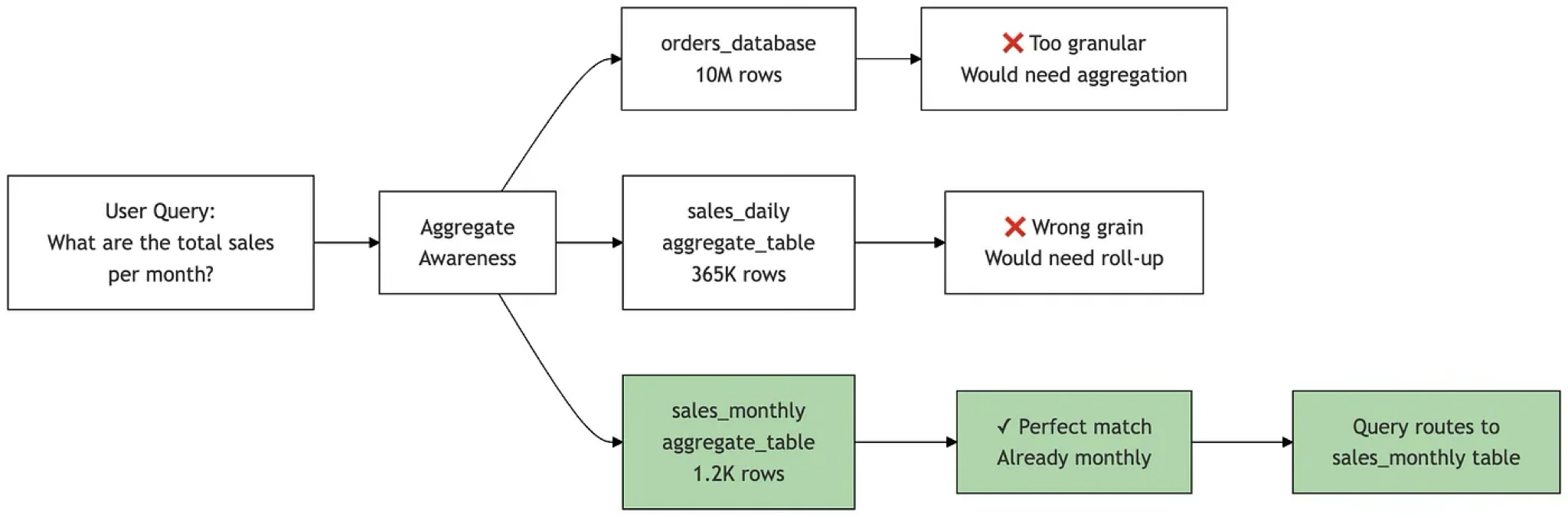
Adventures in Aggregate Awareness (and Level-Specific Measures) with Looker

See you at Coalesce 2024 in Las Vegas, October 7th – 10th 2024
