Automate your Contacts List Segmentation using Google BigQuery, Vertex AI and the ML.GENERATE_TEXT function — Rittman Analytics
When you’re trying to segment your contact list in a CRM tool such as the one we use, HubSpot, one of the challenges is that only some of the data we hold on those contacts is by default available to us in their Hubspot profile.
HubSpot, like most other CRM tools, captures and stores the basic details about a marketing contact such as their name, associated company and the campaign or website activity that introduced them to us, and enriches those basic details with public data such as their LinkedIn bio and Twitter handle.
In previous blogs such as this one on Customer 360 and How Rittman Analytics does Analytics Part 2 : Building our Modern Data Stack using dbt, Google BigQuery, Looker, Segment and Rudderstack I’ve talked about how we extract and centralise the data from our SaaS applications and centralize it in Google BigQuery, giving us a central source of contact data including:
-
Activity on Jira tickets by our own and client staff
-
Signing of statements of work by client sponsors
-
NPS survey scores and feedback given by client stakeholders
-
Summarised communications during the sales and delivery process
-
Ideal Customer Profile (ICP) scores and segments for each client
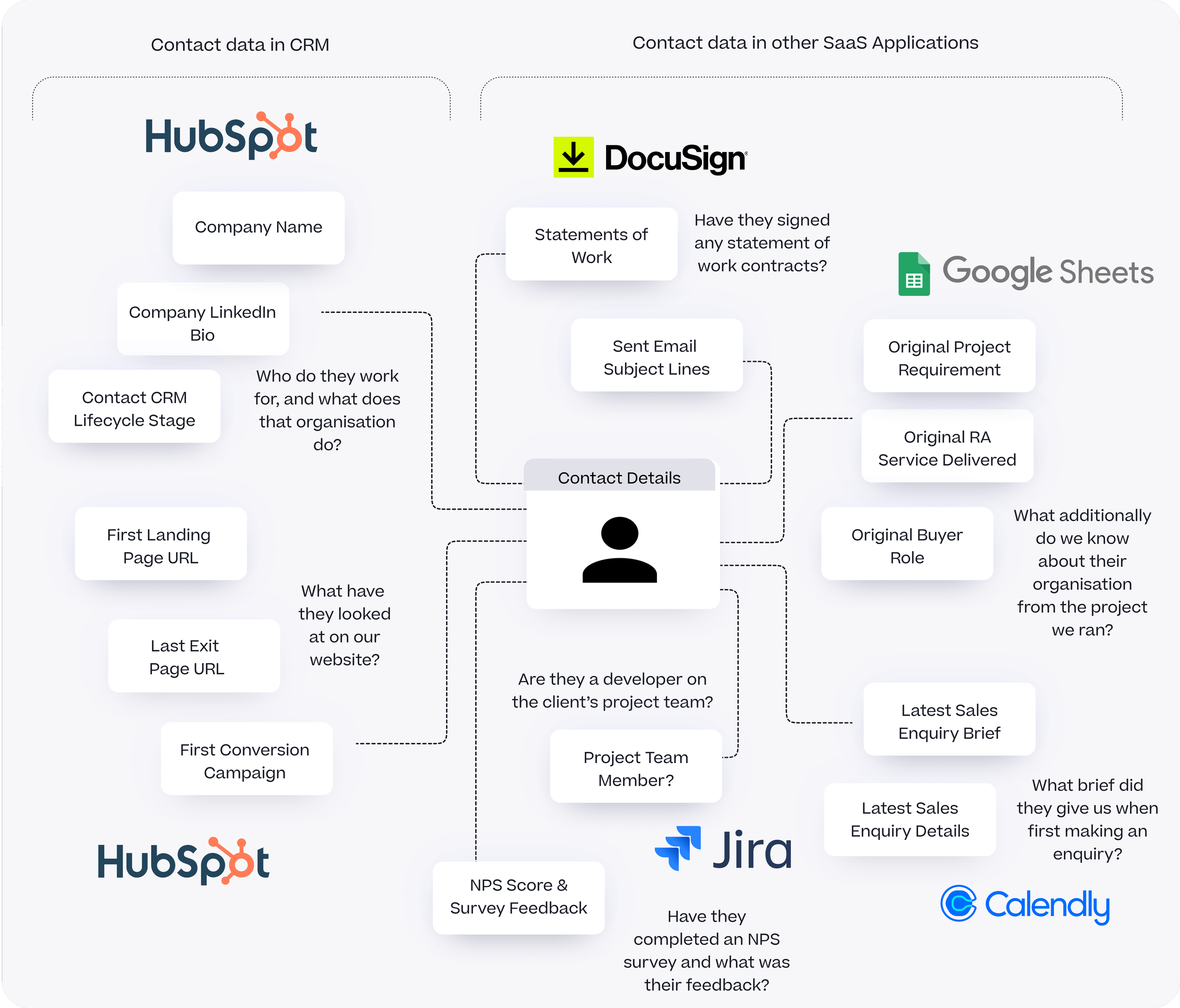
Combining this CRM and activity data for contacts together would, in-theory at least, allow us to add some useful and actionable segments to our contacts list including:
-
The types of analytics consulting services they’re likely to be interested in, based on information discovered in the sales process and projects delivered for that contact in the past
-
The size and nature of the organization they work for, allowing us define audiences of just contacts working for startups, for example
-
Whether the contact is likely to be the decision-maker or budget-holder for their organization, useful of course when working out who is the person who’s going to be signing-off your Statement of Work
I said in-theory though as, whilst the cloud data warehouse makes this rich set of contact available available to marketers, actually deciding which segments to assign to each contact based on the data now available for each of them is quite a laborious, subjective and until now, manual process … in other words, one that’s ideal for automating using generative AI.
The ML.GENERATE_TEXT function that was recently added to Google BigQuery brings ChatGPT-style generative AI to Google SQL, making it possible to use natural language prompts to perform tasks in your data warehouse such as:
-
Classification
-
Sentiment Analysis
-
Entity extraction
-
Extractive Question Answering
-
Summarization
-
Rewriting text in a different style
-
Ad copy generation
-
Concept ideation
Technically a BigQuery remote function call that, under the covers, leverages the various Google Cloud’s Vertex AI large language models (LLMs) to respond to your prompts, ML.GENERATE_TEXT is one of the first manifestations of generative AI in Google BigQuery and one we’ll now use to automate this segmentation of our contacts list.
If you’re familiar with ChatGPT and the way you use “prompts” to pose questions and get answers and explanations either as verbose text or more usefully for us, categorisations or summaries of your data, we need to take the same approach with ML.GENERATE_TEXT to return the set of segment values for each contact.
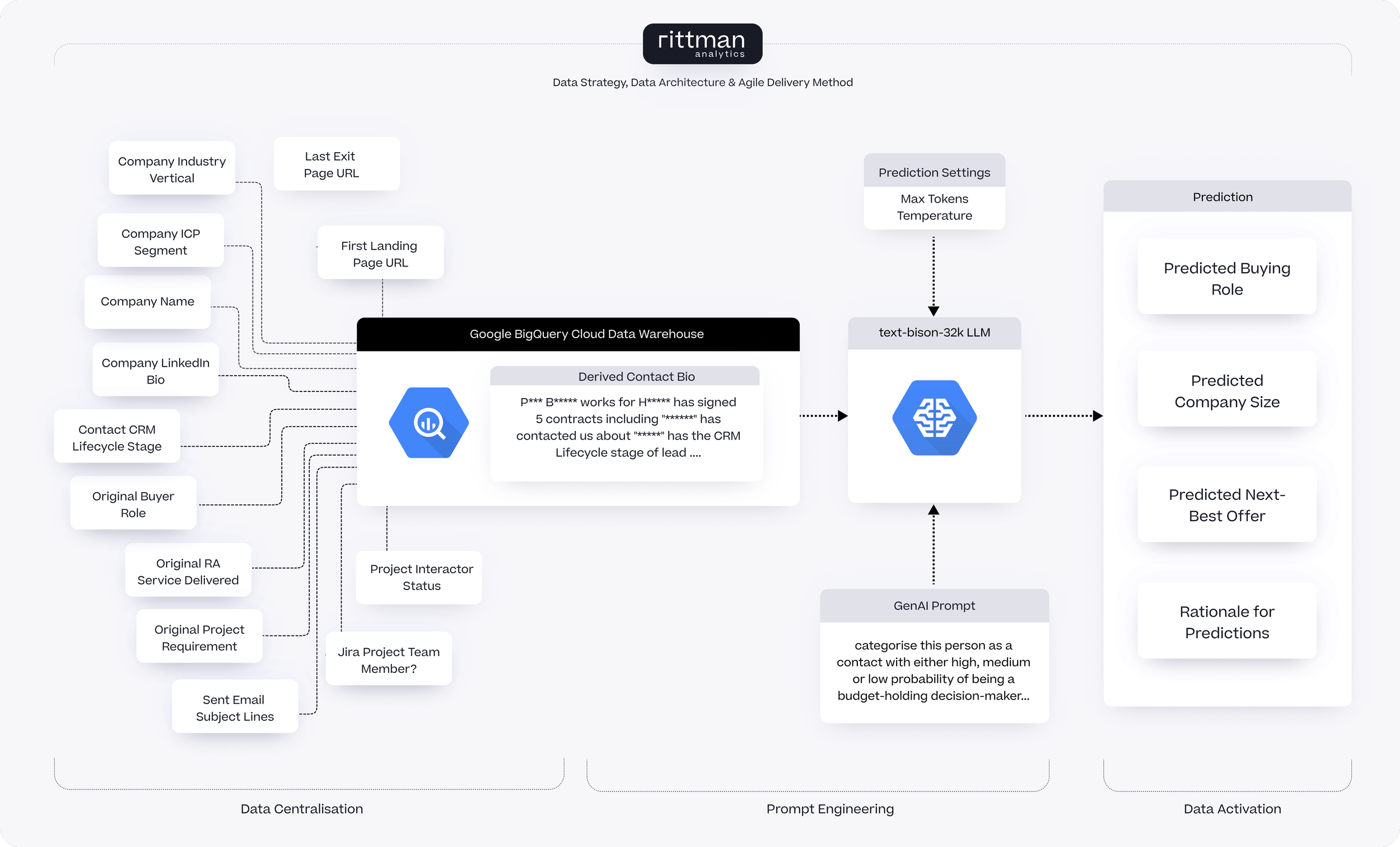
Before we can start prompting our LLM and getting category predictions we first need to setup the connection to a Vertex AI LLM and make it available to BigQuery as a remote function endpoint. To do this, we:
-
Register the LLM we’re going to use in our Google Cloud project, detailed steps for which are in the BigQuery docs and in-summary require you to:
-
Create a cloud resource link from BigQuery, recording the details of the service account and then grant the required IAM roles to this service account, as described in this tutorial
-
Register the Vertex AI text-bison remote model in your GCP project, using the connection name you created in the previous step and selecting
text-bisonas the model endpoint, as per these docs
CREATE OR REPLACE MODEL `ra-development.analytics_ai.bison_model` REMOTE WITH CONNECTION `ra-development.eu.ra-cloudai` OPTIONS (ENDPOINT = 'text-bison');
4. Now we create an SQL query to join together all of the items of data available for each contact and concatenate those details to create a verbose “biography” for that contact that we’ll add to the end of the prompt when sending it to the LLM remote function; for example:
WITH contact_conversations AS ( SELECT conversation_from_contact_name AS contact_name, STRING_AGG(conversation_subject) AS contact_conversation_subjects FROM `ra-development.analytics.conversations_fact` s GROUP BY 1 ), contact_profile AS ( SELECT c.contact_pk, c.contact_name, -- Additional fields and complex COALESCE statements -- Truncated for brevity FROM `ra-development.analytics.contacts_dim` c LEFT JOIN `ra-development.analytics.contact_companies_fact` cc ON c.contact_pk = cc.contact_fk AND contact_next_created_date IS NULL LEFT JOIN contact_conversations s ON c.contact_name = s.contact_name LEFT JOIN `ra-development.analytics.companies_dim` d ON cc.company_fk = d.company_pk LEFT JOIN `ra-development.analytics.contracts_fact` f ON c.contact_pk = f.contact_fk ), contact_profiles_deduped AS ( SELECT contact_pk, contact_name, company_lifecycle_stage, contact_brief, company_name, ideal_customer_group FROM contact_profile GROUP BY 1,2,3,4,5,6 ),
An example contact biography created by this SQL query is shown below, highlighting the elements of that particular biography that the LLM response is likely to consider in its categorisations:

5. Next we’ll design a text prompt that will ask the LLM to classify our contact by the person’s likely service interest, company size and likelihood of being a budget-holding decision maker, such as this one:
Classify this person as one of the following categories of probability of being a budget-holding decision maker in sales activity with us on behalf of their organisation,putting emphasis on their job title and whether they have signed statement of work or project delivery contracts before, (not employment, redundancy or related contracts) and with having no explicit job title reducing that probability, as either
- High
- Medium
- LowAlso predict their categories of consulting services interest from the list
- “Operational Reporting”
- “Marketing Analytics”
- “Data Centralization”
- “Product Analytics”
- “Marketing Attribution”
- “Unknown”separating multiple categories if predicted for a contact using commas, and then predict the category of organization or company that the person works for from
- Startup,
- SMB,
- Mid-Market,
- Enterprise.Give me the rationale your categorisations ensuring any PII is obfuscated in that rationale and do not return any words or comments apart from these three sets of categorisations and rationale. Your response should be in the form of a single line of text that separates each categorisation for the person using a colon, for example:
High:Marketing Analytics,Product Analytics:SMB:Signed statement of work contracts before and has contacted about operational reporting related topics.Text:’
3. Then we decide on the parameter settings that will determine the type, length and predictability of the LLM’s response to our prompt, the most significant of which are listed below:
-
max_output_tokens: An INT64 parameter ranging from 1 to 1024, determining the model's output length. Lower numbers yield brief responses, while higher settings allow for more extensive replies. By default it's set at 50 and tokens, which are smaller than words and roughly equivalent to four characters, mean that 100 tokens translate to about 60-80 words. -
temperature: A FLOAT64 parameter that can range between 0.0 and 1.0, influencing the randomness in the model's responses especially when top_k and top_p are active. Lower temperatures suit straightforward, predictable replies while higher settings encourage varied and imaginative outputs. At 0, the model always chooses the most probable response, with 1.0 being the standard setting. -
top_k: An INT64 parameter value adjustable from 1 to 40 with affects the model's token selection randomness. Lower values lead to more predictable outputs whilst higher ones provide more varied responses, with the default being 40. A top_k of 1 picks the most likely token while a setting of 3 chooses from the top three, incorporating the temperature setting for selection. For each token choice, the model samples from the top_k most probable tokens, further refining them using the top_p value and selecting the final token based on temperature. -
top_p: Set as a FLOAT64 in the range of 0.0 to 1.0, this parameter also steers the randomness of the model's responses. It's set at 1.0 by default. The model selects tokens from the most to the least probable, as determined by top_k, until their combined probability reaches the top_p value. For example, with a top_p of 0.5, if tokens A, B, and C have probabilities of 0.3, 0.2, and 0.1 respectively, the model will choose between A and B, using the temperature value, and exclude C.
As we want the LLM request to return predictable replies, not random and imaginative ones and we want the rationale for the LLM’s predictions to be reasonably concise we choose 0.0 as the temperature and 250 as the max_output_tokens and add the call to ML.GENERATE_TEXT to our SQL query, like this:
WITH contact_conversations AS ( SELECT conversation_from_contact_name AS contact_name, STRING_AGG(conversation_subject) AS contact_conversation_subjects FROM `ra-development.analytics.conversations_fact` s GROUP BY 1 ), contact_profile AS ( SELECT c.contact_pk, c.contact_name, -- Additional fields and complex COALESCE statements -- Truncated for brevity FROM `ra-development.analytics.contacts_dim` c LEFT JOIN `ra-development.analytics.contact_companies_fact` cc ON c.contact_pk = cc.contact_fk AND contact_next_created_date IS NULL LEFT JOIN contact_conversations s ON c.contact_name = s.contact_name LEFT JOIN `ra-development.analytics.companies_dim` d ON cc.company_fk = d.company_pk LEFT JOIN `ra-development.analytics.contracts_fact` f ON c.contact_pk = f.contact_fk ), contact_profiles_deduped AS ( SELECT contact_pk, contact_name, company_lifecycle_stage, contact_brief, company_name, ideal_customer_group FROM contact_profile GROUP BY 1,2,3,4,5,6 ), predictions as ( SELECT contact_pk, contact_name, contact_brief, company_name, ideal_customer_group, ml_generate_text_result['predictions'][0]['content'] AS predicted_decision_maker_type, ml_generate_text_status as prediction_status, FROM ML.GENERATE_TEXT( MODEL `analytics_ai.bison_model`, ( SELECT CONCAT('Classify this person as one of the following categories of probability of being a budget-holding decision maker in sales activity with us on behalf of their organisation,putting emphasis on their job title and whether they have signed statement of work or project delivery contracts before, (not employment, redundancy or related contracts) and with having no explicit job title reducing that probability, as either High,Medium or Low. Also predict their categories of consulting services interest from the list "Operational Reporting", "Marketing Analytics", "Data Centralization", "Product Analytics", "Marketing Attribution" or "Unknown", separating multiple categories if predicted for a contact using commas, and then predict the category of organization or company that the person works for from Startup, SMB, Mid-Market, Enterprise. Give me the rationale your categorisations ensuring any PII is obfuscated in that rationale and do not return any words or comments apart from these three sets of categorisations and rationale. Your response should be in the form of a single line of text that separates each categorisation for the person using a colon, for example: High:Marketing Analytics,Product Analytics:SMB:Signed statement of work contracts before and has contacted about operational reporting related topics. Text:',contact_name,'"',contact_brief,'"') AS prompt, * FROM contact_profiles_deduped order by length(contact_brief) desc limit 50 ), STRUCT( 0.0 AS temperature, 250 AS max_output_tokens)) ) select contact_pk, contact_name, contact_brief, split(string(predictions.predicted_decision_maker_type),':')[safe_offset(0)] as decision_maker_rating, split(string(predictions.predicted_decision_maker_type),':')[safe_offset(1)] as predicted_interest, split(string(predictions.predicted_decision_maker_type),':')[safe_offset(2)] as predicted_company_size, split(string(predictions.predicted_decision_maker_type),':')[safe_offset(3)] as rationale, coalesce(trim(prediction_status),'OK') as prediction_status from predictions
Running this SQL query gave us predicted category segment values for (most of) the contacts within the scope of this query, with the split and safe_offset() string functions splitting out the various categorisation types from the LLM’s response, as you can see from the screenshot below.

I say “most” of the contacts because some significant restrictions apply to using ML.GENERATE_TEXT in set-based data transformations like these, the most significant being a quota limit of 60 requests per minute that if exceeded return a RESOURCE EXCEEDED error message and no request response.
Working around this limit therefore requires batching-up and sending requests using a shell script or another approach such as the ones described here, not an impossible thing to do but it does effectively rule this feature out as a part of batch-style transformations in a dbt project, for example.
The most likely scenario therefore is one where we batch-up these categorisations and output the results to a file or BigQuery table as a one-off or infrequently-scheduled process and then use the results to either create another table in the warehouse that we join-back to our contacts data, or use as the data source in a reverse ETL sync to HubSpot using a service such as Hightouch or Rudderstack Reverse ETL.
Interested? Find Out More!
Rittman Analytics is a boutique data analytics consultancy that helps ambitious, digital-native businesses scale-up their approach to data, analytics and AI.
We’re authorised delivery partners for Cube, Dagster, Preset, dbt Labs, Fivetran, Rudderstack and Snowflake along with Google Cloud, Oracle, Segment and Lightdash and are experts at helping you choose the right ones for your organisation’s needs, use-cases and budget and working with you and your data team to successfully implement them.
If you’re looking for some help and assistance with your AI initiative or would just like to talk shop and share ideas and thoughts on what’s going on in your organisation and the wider data analytics world, contact us now to organise a 100%-free, no-obligation call — we’d love to hear from you!
CEO of Rittman Analytics, host of the Drill to Detail Podcast, ex-product manager and twice company founder.
Recommended Posts

Drill to Detail Podcast Transcripts & Gen AI Insights Now Available, Powered by OpenAI Whisper API & BigQuery Colab Notebooks
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
Opinionated, AI-Enabled & Modern: The Story Behind Rittman Analytics’ New Website
