Oracle Big Data Cloud, Event Hub and Analytics Cloud Data Lake Edition pt.2
A couple of weeks ago I posted a blog on Oracle Analytics Cloud Data Lake Edition and the Oracle Cloud big data products you’d typically use to create a cloud-hosted, object storage data lake. In this and the final post in the series I’m going to look at some of the data transformation and predictive model building features that come with the Data Lake Edition of OAC and extend the base capabilities in this area that OAC Standard Edition comes with, and the data engineering role that uses the data lake this Oracle Analytics Cloud product packaging option is designed for.
As a reminder, OAC Standard Edition is more-or-less Oracle Data Visualization running as a single-tenant cloud-hosted VM (cluster) that’s either customer managed, or Oracle-managed if you go for the new Autonomous Analytics Cloud that interestingly is charged at a lower hourly rate than the customer-managed version; presumably it costs Oracle less to run OAC when it’s doing all the administration rather than letting customers control the settings, which makes sense.
It does make you wonder when all this VM nonsense will go away though as well as the distinction between OAC and the DVCS/BICS managed service cloud analytics products, with all of these services just becoming packaging options for a multitenant service partitioned by customer instance as the likes of Looker and Google Cloud Platform do today.
But for now, Oracle Analytics Cloud Data Lake Edition is described on the product homepage as having the following high-level capabilities compared to OAC Standard Edition:

- Accelerated analysis via Essbase
- and support for creating scalable, shareable high performance data flows.
whilst the product documentation states that it includes all the OAC Standard Edition features, plus:
- Explore and replicate data
- Create scalable data flows including ingestion, transformation, and persistence
- Execute data flows by using Apache Spark or Oracle Database Cloud
with two edition-specific scenarios listed:
- Explore Data Lakes, described as “You can create data flows to visualize data in your data lakes”, and
- “Replicate Data in Data Lakes”, explained as “You can replicate data from Oracle Service Cloud (RightNow) into Oracle Big Data Cloud Service, Oracle Database Cloud, and Oracle Database. For example, you can replicate data from customer service records in Oracle Service Cloud into your data lake on Oracle Big Data Cloud Service and then perform further data preparation and analysis with data flows and data visualization projects.”
I’m guessing most readers won’t have heard of Oracle Service Cloud but for Oracle Cloud customers it’s quite a useful initial integration, as Service Cloud is Oracle’s cross-channel digital customer call centre application that brings together customer service interactions across web, social media and offline service channels. More interestingly though and you may have missed it back at the start but Data Lake Edition is the edition that ships Essbase, Oracle’s multi-dimensional OLAP server, in what almost seems like an afterthought right now but will become, I suspect, a more significant defining feature of this product package as time goes on.
For the purposes of this series of blog posts though, what I’m really interested in are the data engineering features in OAC Data Lake Edition — but before I start looking into what they might be, I guess I’d better explain what I mean by a data engineer.
I first came across the term data engineer in a blog written by Curt Monash — still the #1 person I’d love to have come on the Drill to Detail Podcast, if you happen to read this Curt — where he wrote:
“I learned some newish terms on my recent trip. They’re meant to solve the problem that “data scientists” used to be folks with remarkably broad skill sets, few of whom actually existed in ideal form. So instead now it is increasingly said that:
- “Data engineers” can code, run clusters, and so on, in support of what’s always been called “data science”. Their knowledge of the math of machine learning/predictive modeling and so on may, however, be limited.
- “Data scientists” can write and run scripts on single nodes; anything more on the engineering side might strain them. But they have no-apologies skills in the areas of modeling/machine learning.”
I think it’s probably true to say that the term really started to enter people’s consciousness, at least the sorts of people I hang around with, when Maxime Beauchemin from Airbnb wrote his seminal blog “The Rise of the Data Engineer” where he introduced this new discipline as:
“Like data scientists, data engineers write code. They’re highly analytical, and are interested in data visualization.
Unlike data scientists — and inspired by our more mature parent, software engineering — data engineers build tools, infrastructure, frameworks, and services. In fact, it’s arguable that data engineering is much closer to software engineering than it is to a data science.
In relation to previously existing roles, the data engineering field could be thought of as a superset of business intelligence and data warehousing that brings more elements from software engineering. This discipline also integrates specialization around the operation of so called “big data” distributed systems, along with concepts around the extended Hadoop ecosystem, stream processing, and in computation at scale.
In smaller companies — where no data infrastructure team has yet been formalized — the data engineering role may also cover the workload around setting up and operating the organization’s data infrastructure. This includes tasks like setting up and operating platforms like Hadoop/Hive/HBase, Spark, and the like.”
Maxime’s blog struck a chord with me as that’s pretty much how I’d describe what I do, or at least it’s the work I most enjoy doing; building big data systems to support BI and data warehousing workloads where my knowledge of how Hadoop, cloud and distributed data platforms complements the knowledge that other colleagues have around data science, machine learning and statistical analysis though importantly, I know enough about those areas to be able to deploy the models they build (or as we say over in the UK at least, I know enough about them to be dangerous).
I interviewed Maxime about his blog and the topic of data engineering on the Drill to Detail Podcast last May and if you’ve not done so already I’d recommend you give the episode a listen; for me though, having just spent the last eighteen months working in the London tech startup scene, my definition of a data engineer would be someone who’s just out of university and has an ironic beard, thinks he’s made ETL tools obsolete but is slowly, painfully, recreating one and is now just on the brink of discovering code templating, deployment contexts, change control and data lineage…

… but earns twice what you earn and gets all the girls. Because, data engineers are even more essential than data scientists if you’re serious about building a data lake, and data lakes are the new data warehouses.
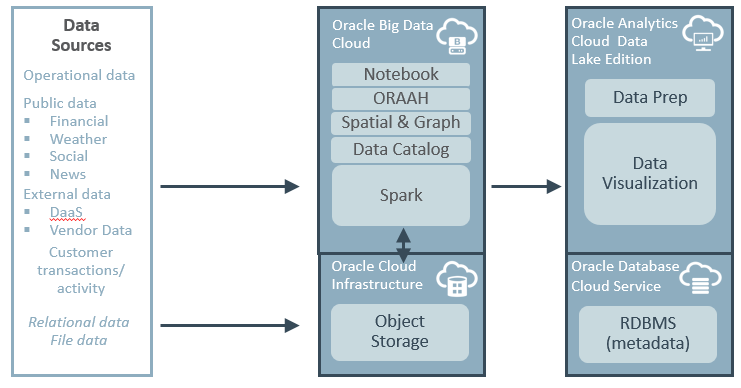
Which bring us back to Oracle Analytics Cloud Data Lake Edition and these three blog posts. The first part of this three part series talked about Oracle Big Data Cloud and products such as Oracle Event Hub Cloud — Dedicated (who names these products at Oracle? Seriously?) and in this second I seem to have got rather diverted by trying to define what Oracle Analytics Cloud Data Lake Edition actually is and then even more so by defining the supporting role of a data engineer; in the final post tomorrow I’ll take a look at some of the data transformation, model definition and deployment and data engineering features in OAC Data Lake Edition and then, finally, conclude by asking myself two questions — OK, three:
- Has OAC Data Lake Edition got anything actually to do with data lakes, and is it a useful tool for aspiring Oracle technology data engineers?
- How does it compare to my old favourite Oracle big data product Oracle Big Data Discovery, officially still available and not quite dead yet but existing in some strange zone where the on-premises version stopped getting updates a while ago and the cloud version is for sale but you can’t buy it unless you know the right person to ask and he’s actually gone to Cloudera
- Will the ironic beard and quiff be enough, or do I need to go full ginger if I’m going to really be taken seriously as a data engineer?

Final part in the series on Oracle Analytics Cloud Data Lake Edition comes later this week.