Google BigQuery, and Why Big Data is About to Have its GMail Moment
If like me you ran your own email server back in the 90’s and spend evenings and weekends keeping it running and wondering what all the fuss was about open relays, or you remember using Outlook around that same time and working with tiny mailbox quotas and seemingly constant Exchange Server outages, you’ll probably remember how revolutionary Google’s GMail service seemed in 2004 with more-or-less unlimited storage, one of the first AJAX JavaScript rich web clients and all of the backend infrastructure taken care of by Google.
Fast-forward to today and it’s increasingly common to see what’s now Google Apps deployed across large corporations, universities and even government deparments as they switch to buying email, calendering and file storage as services rather than own and manage the infrastructure themselves, and users benefit by having a more reliable service that always has enough capacity to meet their needs.
Contrast this with the state of Hadoop and on-premise big data systems today, where its not unusual to wait months for corporate IT to add a new cluster or expand capacity on existing ones as they in turn wait for procurement to negotiate a deal and then pass the work to an outsourced managed service provider to finally have it provisioned in the data centre – if there’s still some CapEx budget left, otherwise try again next year. Hadoop system administration is still a bit of a black art and few of us have the skills and experience to manage and keep secure clusters of thousands or even hundreds of server nodes … but that exactly what the likes of Google, Microsoft, Amazon Web Services and Oracle do for a living, and as I blogged about a few months ago they’re now selling object-level storage, Spark and streaming ingestion as services you connect to and consume, billed monthly based on numbers of users or some other metric and never having worry about upgrades, cluster administration or replacing a faulty node.
Final state of my home automation + wearables datalake project as I finish sabbatical – now ported to GCS, Google BigQuery & Data Studio pic.twitter.com/pTNjvImHcU
— Mark Rittman (@markrittman) November 4, 2016
And in the same way I worked out that my time was better spent learning Oracle development rather than running a mail server, the Hadoop cluster I’ve been tinkering with in the garage is likely to go the same way as I port my home development work over to Google’s cloud platform and think of my big data platform as elastic compute and storage services that always work and scale-up when needed … and as big data and data warehousing platforms converge as they transform into managed cloud services, big data doesn’t necessarily have to be Hadoop, HDFS and unstructured data stores.
Google famously invented the core Google File System and MapReduce technologies that Doug Cutting and Mike Cafarella then reimplemented as the open source Apache Hadoop project, but Google then went on to create Dremel, a distributed ad-hoc query system better suited to data warehouse-type workloads than batch-orientated MapReduce, ran over tens of thousands of servers in Google’s data centres and stored its data in column-oriented format (and in-turn inspired another open-source project, Apache Drill)
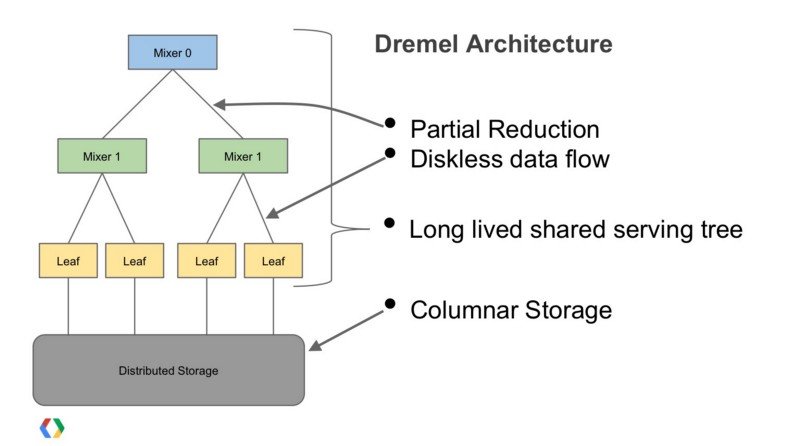
Google have now made a public version of Dremel, Google BigQuery, available as a service within Google Cloud Platform and conceptually it’s similar to the Apache Kudu and Apache Impala projects that Mike Percy and I discussed in Episode 3 of the Drill to Detail podcast; specialised storage optimised for analytic workloads with data stored in a tabular format and a SQL query engine designed to work with BI tools that support BigQuery as a data source through its API and distinct SQL dialect, or more recently a JDBC interface and ANSI SQL.
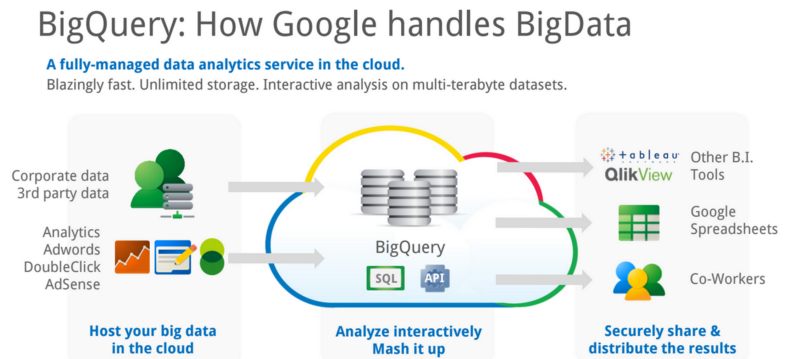
As I showed in my tweet about BigQuery I’ve been using it and its ability to use Google Sheets as external table sources to land and query my home IoT and wearables data, gradually building in real-time ingestion and loading using Google PubSub and Google Cloud DataFlow, to receive and then transform incoming IoT events in a pipeline that feeds data into BigQuery as streaming row inserts.
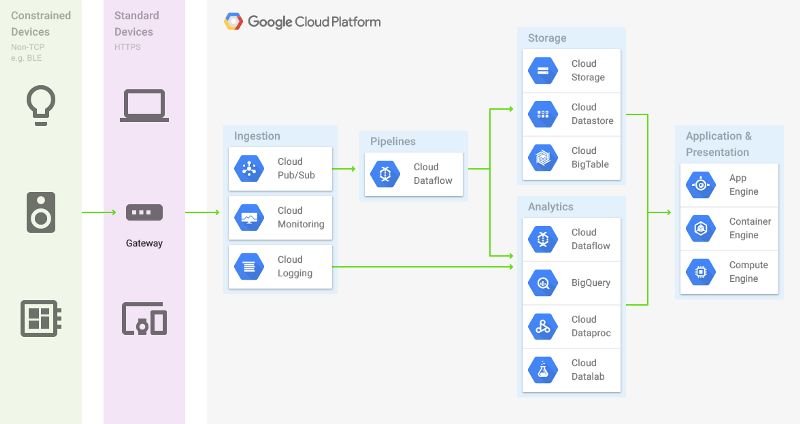
What’s interesting is that Google Cloud Platform and Google BigQuery is the technology that ended-up powering the type of Customer 360 applications I talked about around this time last year.
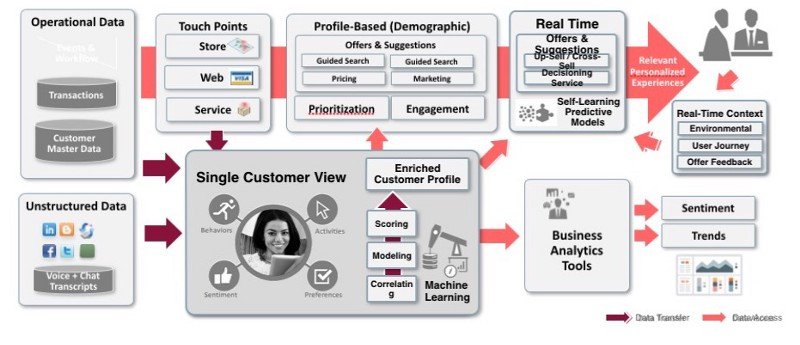
While most Customer 360 and digital marketing initiatives start on in-house Hadoop clusters or cloud-based services such as Amazon Redshift, the petabyte-scale of event-based customer interaction records means that it’s easier, cheaper and far less work to hand this sort of workload off to Google and have developers concentrate on delivering new experiences and offers to customers rather than plugging in another truckload of servers into the cluster to try and keep up with demand. But the story behind that is one for another day … and it’s good.
Recommended Posts

Agentic Data Platform Migration using Wire, Claude Code and Rittman Analytics

One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery

Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
Recent Posts
Agentic Data Platform Migration using Wire, Claude Code and Rittman Analytics
Making Agentic Analytics More Accurate using Anthropic’s Agentic Data Stack and the Wire Framework
Google Next 2026: What’s New for Looker, BigQuery, Data Platforms and Agentic Analytics
Introducing the Wire Framework: The “Secret Sauce” Behind Our AI-Augmented Analytics Project…
So, Just How Relevant is Multi-Touch Attribution to Marketers in 2026?
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
Rittman Analytics 2025 Wrapped : A Year of Platforms, People and High-Performing Data Teams
You Probably Don’t Need an RFP
