Building Predictive Analytics Models against Wearables, Smart Home and Smartphone App Data — Here’s…
Earlier today I was the guest of Christian Antognini at the Trivadis Tech Event 2016 in Zurich, Switzerland, presenting on the use of Oracle Big Data Discovery as the “data scientists’ toolkit”, using data from my fitness devices, smart home appliances and social media activity as the dataset. The slides are here:
https://www.slideshare.net/rittmanmead/using-oracle-big-data-discovey-as-a-data-scientists-toolkit
Whilst the main focus of the talk was on the use of BDD for data tidying, data visualisation and machine learning, another part of the talk that people found interesting but that I couldn’t spend much time on was how I got the data into the Hadoop data lake I put together to hold the data. Whilst the main experiment I focused on in the talk just used a simple data export from the Jawbone UP website (https://jawbone.com) to get my workout, sleep and weight data, I’ve since gone on to bring a much wider set of personal data into the data lake via two main routes;
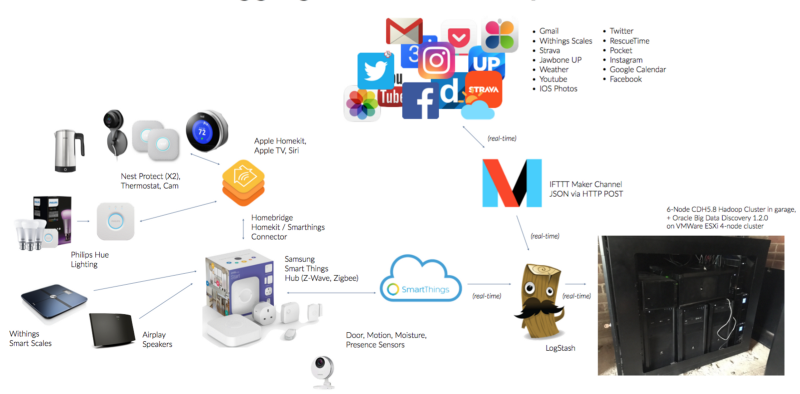
-
IFTTT (“If this, then that”) to capture activity from UP by Jawbone, Strava, Instagram, Twitter and other smartphone apps which it then sends in the form of JSON documents via HTTP GET web requests to a Logstash ingestion server running back home for eventual loading in HDFS, then Hive via Cloudera’s JSONSerde
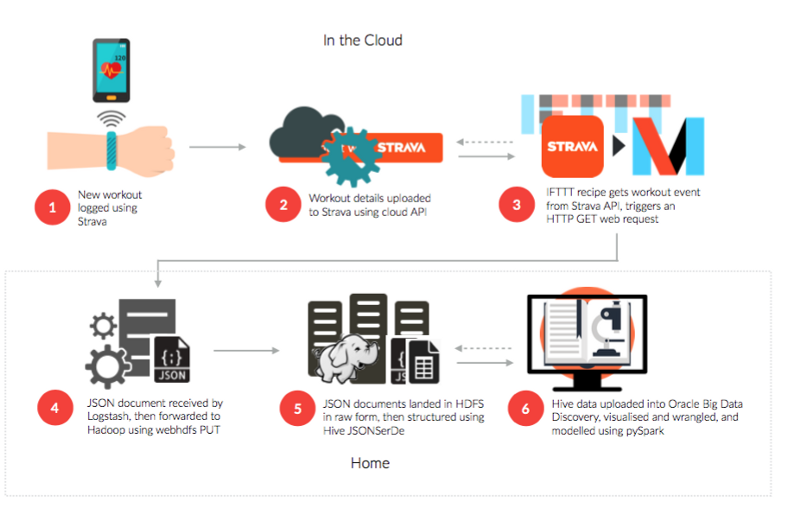
-
A Samsung Smart Things “smartapp” that subscribes to smart device and sensor activity in my home, then sends those events as JSON documents again via HTTP GET web requests to Logstash, again for eventual storage into HDFS and Hive and hourly uploads into Big Data Discovery’s DGraph NoSQL engine
This all works well and means that my dashboards and analysis in Big Data Discovery are at most one-hour behind the actual activities that take place in my smartphone apps or in my home amongst the various connected heating thermostats, presence sensors and other devices eventually feeding their activity through my Samsung Smart Things hub and the smartapp that I’ve got running in Samsung’s Smart Things cloud service.
More recently though I’ve got the same activity also loading into Apache Kudu, the new real-time fast analytics storage layer for Hadoop, using a new Hadoop ETL tool called “Streamsets” that streams data in real-time into Kudu and Cloudera Impala from a variety of source types.
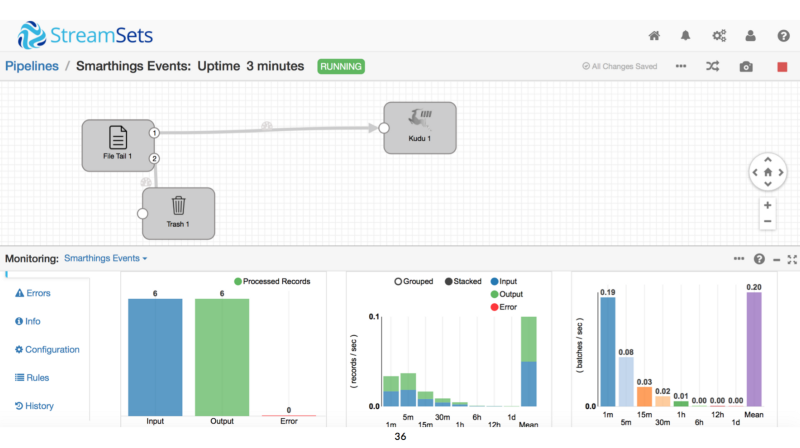
This additional data loading and storage route now gives me metrics in actual real-time (not the one-hour delay caused by BDD’s DGraph hourly batch load), and gives me the total and complete set of events and not the representative sample that Big Data Discovery normally brings in via a DGraph data processing CLI load.
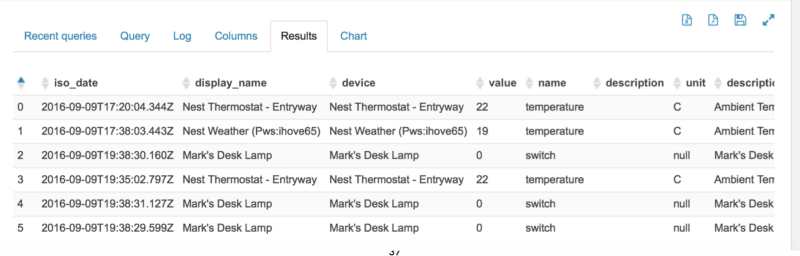
Eventually the aim is to connect it all up via Kafka, but for now it’s a lovely sunny day in Zurich, I’m meeting Christian Berg for a beer and lunch in 30 minutes, so I think it’s time for a well-deserved afternoon-off, and then prep for my final speaking commitment before Oracle Openworld next week … Dublin on Monday to talk about Oracle Big Data.
Recommended Posts

One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery

Agentic Data Platform Migration using Wire, Claude Code and Rittman Analytics

Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
Recent Posts
Agentic Data Platform Migration using Wire, Claude Code and Rittman Analytics
Making Agentic Analytics More Accurate using Anthropic’s Agentic Data Stack and the Wire Framework
Google Next 2026: What’s New for Looker, BigQuery, Data Platforms and Agentic Analytics
Introducing the Wire Framework: The “Secret Sauce” Behind Our AI-Augmented Analytics Project…
So, Just How Relevant is Multi-Touch Attribution to Marketers in 2026?
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
Rittman Analytics 2025 Wrapped : A Year of Platforms, People and High-Performing Data Teams
You Probably Don’t Need an RFP
