Stitching Identity Across the Customer Journey Using Segment, Google BigQuery and Looker
Last week in my previous blog “How Rittman Analytics does Analytics Part 2 : Building our Modern Data Stack using dbt, Google BigQuery, Looker, Segment and Rudderstack” I went through how we’ve built our own modern data stack and use it to record and analyze client interactions from initial sales enquiry through to invoicing and renewal, by creating a unique record for each of our clients and using it to link together all of their activity in Xero, Hubspot, Jira and our other SaaS applications.

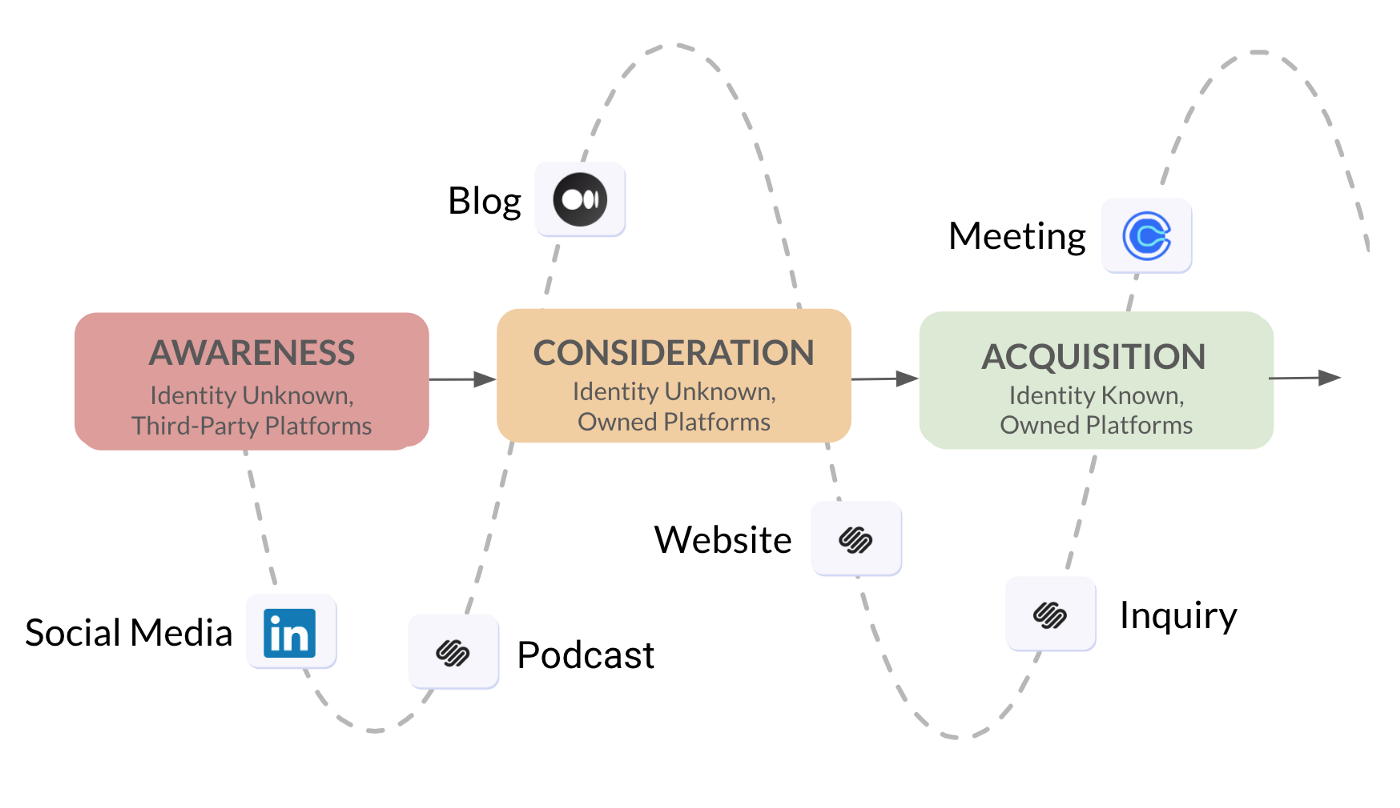
By centralizing all of this client activity in a cloud data warehouse one of the most valuable use-cases we have for this data is to help us understand our customer journey, from initial awareness through to service and (if all goes well) loyalty.

Data from Hubspot, Xero and our other SaaS applications helps us connect our customer touchpoints at the acquisition, service and loyalty stages but what about the ones before acquisition, when prospects come to our site anonymously or visit our profiles on LinkedIn or Twitter? When they only reveal who they are by booking a meeting on Calendly, how do we link those identities to the anonymous visits they’ve made to our website?
In this blog I’ll explain how we connect prospect and client activity together across all of the stages in our customer journey, and how we try and extend this customer journey to platforms we don’t own or control but do provide some limited information on who’s interested in our content and services. I’ll use Segment for the examples but we do something similar with tracking data we get from Rudderstack and Snowplow which use similar concepts around tracking and identifying users and their behavior.
Tracking Anonymous Activity on your Site
Starting with the simplest example of a visitor arriving at our website and browsing a series of pages, all of that activity would be anonymous but connected via their anonymousId, a randomly generated 36 character string automatically assigned to the user’s browser or device on first visit.

This cookie-stored first-party visitor ID will persist between sessions for up to twelve months but expires after seven days of inactivity when stored in browsers based on Apple’s WebKit engine, for example Safari on MacOS or all browsers on running on iOS.
The impact of this eventual expiry is that an individual user visiting your site may have multiple IP addresses associated with a single anonymousId, and second or multiple other anonymousIds linked to different devices or the same device used after an extended period of inactivity.
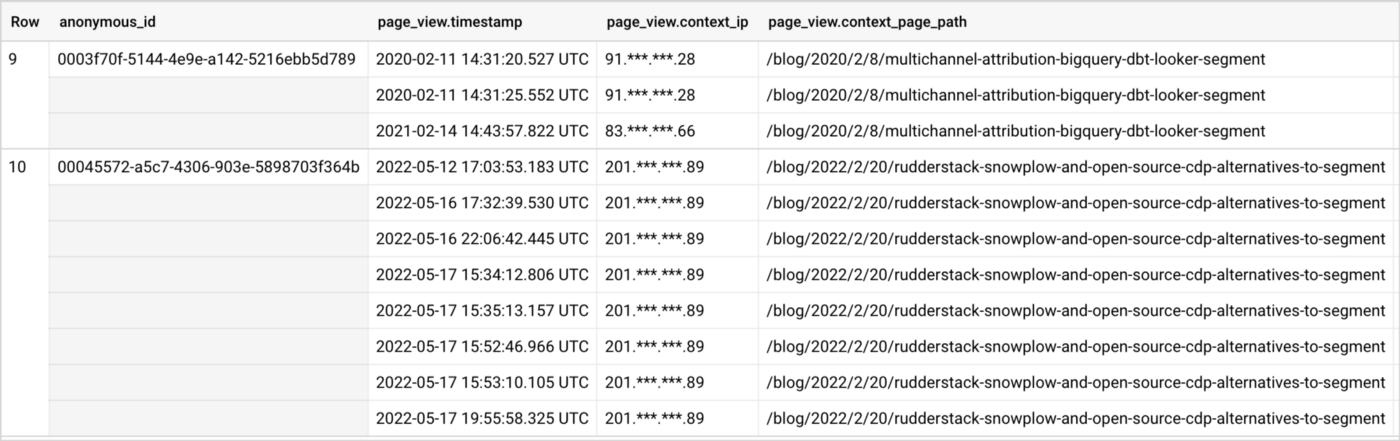
We can see this in our Segment event data stored in our Google BigQuery data warehouse by querying it and then grouping by anonymousId (note that the SQL expression around the context_ip column was added to obfuscate IP addresses in the example output here and later in this blog)
selectanonymous_id,array_agg(struct(timestamp,concat(split(context_ip,'.')[safe_offset(0)],'.***.***.',split(context_ip,'.')[safe_offset(3)]) as context_ip,context_page_path,context_page_referrer,context_page_title,context_user_agent)order by timestamp) page_viewfrom`ra-development.company_website.pages`group by1order by1
See how the for the first anonymousId the IP address is constant, whereas for the second their IP address has changed over time; in addition, both of these anonymousIds may in-fact be linked to the same person, you just wouldn’t know it from the data as its currently shown.
The way we link two or more anonymousIds and their activity together is by your website or app sending an Identify event, ideally each time a user logs in and identifies themselves or provides you with useful information such as channel or product preferences that you want stored in their user profile.
However … like most consulting websites ours doesn’t allow visitors to create accounts or log in, something that’s typical of sites that either aren’t transactional or are but don’t want to introduce unnecessary friction to their checkout process.
Linking Offsite Conversions to Onsite Anonymous Activity
We don’t have a checkout on our site but we do have what we consider as our conversion event; when a visitor books a meeting with us using our Calendly service, either by pressing one of the Contact Us buttons on various pages on the site or by filling in the contact form on our home page.
Both conversion methods collect the visitor’s name, email address and reason for enquiring and, short of having a user login and ability to register for an account, are the best we’re going to get for our site in-terms of users identifying themselves. Whilst Segment’s best practices advises against using email as UserId as it can vary over time for someone, we use it as ID at prospect stage and then consolidate all emails and source system IDs into single contact records once they appear in Hubspot, our CRM system.

Calendly doesn’t directly integrate with Segment but does have an integration with Zapier, which means we can set-up a routine or “Zap” that triggers when a Calendly event is booked and then sends two events to Segment via its HTTP API; a track event to record the booking being made followed by an identify event that we use to link these anonymous visitor activities to an email address and prospect name.

Normally a SaaS application event captured by Zapier and sent to Segment would not be aware of the visitor website session that originated it, as it would be Calendly that triggered the routine to run as far as Zapier was concerned.
However it is possible to pass information via UTM parameters we add to the e Calendly API calls we attach to the Contact Us buttons on our website, for example using the code snippet below:
<script>var links = document.getElementsByClassName("sqs-block-button-element");for (i = 0; i < links.length; i++) {links[i].addEventListener('click', function() {Calendly.initPopupWidget({url:'https://calendly.com/markrittman/initial-discovery-call-with-mark-rittman?utm_source=rittmananalytics.com&utm=medium=website&utm_campaign=homepage_hero_image&utm_term='+analytics.user().anonymousId()});return false;});};</script>
We use this ability to pass the visitor anonymousId to Calendly via the otherwise unusedutm_term parameter, which the Calendly API then makes available back to us in Zapier and we use in the track and identify events we send to Segment.

There’s one other source of identification I can make use of at this Consideration stage of our customer journey; the email address we embed in each link URL and we can extract from the page URL querystring in any page view event that is the result of one of those links being clicked.
coalesce(split(split(context_page_url,'ajs_aid=')[safe_offset(1)],'&')[safe_offset(0)],user_id) as user_id,
Then, if the visitor returns at a later date with a different AnonymousId and books a second meeting using the same email address, both sets of events and anonymousIds in the downstream warehouse can be linked via their common UserId.

The way you do this linking of anonymousIds their common UserIds is by using ID-stitching logic such as the excerpt from this full SQL query below:
...id_stitching as (selectdistinct anonymous_id as anonymous_id,last_value(user_id ignore nulls) over (partition by anonymous_id order by timestamp rows between unbounded preceding and unbounded following ) as user_id,min(timestamp) over (partition by anonymous_id ) as first_seen_at,max(timestamp) over (partition by anonymous_id ) as last_seen_atfromevents ),mapped as (selectcoalesce(i.user_id,e.anonymous_id) as blended_user_id,e.*fromevents eleft joinid_stitching iusing(anonymous_id)),names_backfilled as (select* except (name,email),last_value(email ignore nulls) over (partition by blended_user_id order by timestamp rows between unbounded preceding and unbounded following ) as email,last_value(name ignore nulls) over (partition by blended_user_id order by timestamp rows between unbounded preceding and unbounded following ) as namefrommapped ),...
If you then use the name and email address you’ve now obtained for this UserId and use it to back-fill all of the events that only had anonymousIds, you can then group each users’s events by those details and output those as a more complete record of each user’s behavior at the Consideration stage of the user journey.

We can use this data to understand, for example. the most common user journeys that are a result of visitors landing on some of our blog posts, with the first step in this analysis being to pivot each users’ page views into a series of columns for first page viewed, second page viewed and so on.
If we then paste this query in Looker’s SQL Runner and visualize the results using the Sankey data vizualization plug-in available on the Looker Marketplace, I can see that our article on Multi-Channel Attribution had by far the most initial visitors and widest range of subsequent page views.

Or I can visualize this visitor journey as a Looker table visualization, pivoting the event sequence number and setting page title as a measure (SQL here).

Tracking Offsite Activity
So far we’ve just looked at the Consideration stage in our customer journey, but what about the Awareness stage? Taking our business as an example, our client journeys often start by someone first becoming aware of us through an article posted on Twitter, LinkedIn or Medium and then some time later, following a link to our site and finding out about our services.
The common factor in all these Awareness-stage interactions is that they happen on platforms that we don’t control; we can’t add Segment tracking code to our profile page on LinkedIn, for example, and by default can only make use of UTM parameters in article URLs to give us a general sense of where site traffic is coming from.
What is also possible though using scraping services such as PhantomBuster is to collect some limited details of interactions with our content on sites like LinkedIn, providing us with the names and in some cases email addresses of users interacting with our content and the nature of those interactions, for example liking a post or following our profile.
Using the user’s name and potentially their email address it’s possible to then infer that they are the same people who’ve visited our site, once they later identify themselves by booking a meeting, by matching those social media users to our known users by name.

What’s important to remember with this type of identity stitching is that, unlike positive link we make between activities on our website and Calendly bookings by passing across the visitor’s AnonymousID, in this instance we’re inferring the link by connecting people by just their name.
As such, we add a boolean flag to each event record to indicate whether the visitor identity is inferred or not, as shown in the excerpt below from the full and final SQL query here.
selectblended_user_id,name,email,logical_or(is_inferred_identity) as is_inferred_identity,array_agg(struct(timestamp,event_type,context_ip,anonymous_id,user_id,is_inferred_identity,context_page_path,context_page_referrer,context_page_title,context_user_agent,context_campaign_source,context_campaign_medium,context_campaign_source,requirement)order by timestamp) eventfrom names_backfilledgroup by 1,2,3
The output from this final query allows us to finally stitch together the off-platform Awareness stage of our customer journey with the anonymous and subsequently-identified Consideration stage activity of visitors to our website, as shown for example for myself in the final screenshot below.

Interested? Find out More
Rittman Analytics is a boutique analytics consultancy specializing in the modern data stack who can help you centralise your data sources and enable your end-users and data team with best practices and a modern analytics workflow.
If you’re looking for some help and assistance understanding and analysing your customer journey, or to help build-out your analytics capabilities or data warehouse on a modern, flexible and modular data stack, contact us now to organize a 100%-free, no-obligation call — we’d love to hear from you and see how we might help you and your team build your own modern, ELT-style modern data stack.